import wandb
from datasets import load_dataset
# if you can't find libwebp library, use brew update && brew install webp
import evaluate
import numpy as np
import torch
from transformers import TrainingArguments
from trl import SFTTrainer
from transformers import (
AutoModelForCausalLM, AutoTokenizer, AutoConfig,
LlamaConfig, LlamaModel,
)
from transformers import GenerationConfig
from transformers.integrations import WandbCallback
from tqdm import tqdm
def token_accuracy(eval_preds):
token_acc_module = evaluate.load("accuracy")
logits, labels = eval_preds
# shape: batch_size x max_sequence_length
predictions = np.argmax(logits, axis=-1)
# accuracy only accepts 1d array. So if the batch contains > 1 datapoints,
# the accuracy is based on flattened arrays
# https://huggingface.co/spaces/evaluate-metric/accuracy
return token_acc_module.compute(
predictions=predictions.flatten().astype(np.int32),
references=labels.flatten().astype(np.int32),
)
def prompt_no_input(row):
return ("Below is an instruction that describes a task. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Response:\n{"
"output}").format_map(
row
)
def prompt_input(row):
return (
"Below is an instruction that describes a task, paired with an input "
"that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### "
"Response:\n{output}").format_map(
row
)
def create_alpaca_prompt(row):
return prompt_no_input(row) if row["input"] == "" else prompt_input(row)
class LLMSampleCB(WandbCallback):
def __init__(
self, trainer, test_dataset, num_samples=10, max_new_tokens=256,
log_model="checkpoint"
):
super().__init__()
self._log_model = log_model
def create_prompt_no_anwer(row):
row["output"] = ""
return {"text": create_alpaca_prompt(row)}
self.sample_dataset = test_dataset.select(range(num_samples)).map(
create_prompt_no_anwer
)
self.model, self.tokenizer = trainer.model, trainer.tokenizer
self.gen_config = GenerationConfig.from_pretrained(
trainer.model.name_or_path,
max_new_tokens=max_new_tokens
)
def generate(self, prompt):
tokenized_prompt = self.tokenizer(prompt, return_tensors='pt')[
'input_ids']
with torch.inference_mode():
output = self.model.generate(
inputs=tokenized_prompt, generation_config=self.gen_config
)
return self.tokenizer.decode(
output[0][len(tokenized_prompt[0]):], skip_special_tokens=True
)
def samples_table(self, examples):
records_table = wandb.Table(
columns=["prompt", "generation"] + list(
self.gen_config.to_dict().keys()
)
)
for example in tqdm(examples):
prompt = example["text"]
generation = self.generate(prompt=prompt)
records_table.add_data(
prompt, generation, *list(self.gen_config.to_dict().values())
)
return records_table
def on_evaluate(self, args, state, control, **kwargs):
super().on_evaluate(args, state, control, **kwargs)
records_table = self.samples_table(self.sample_dataset)
self._wandb.log({"sample_predictions": records_table})
print("log once")
def param_count(m):
params = sum([p.numel() for p in m.parameters()]) / 1_000_000
trainable_params = sum(
[p.numel() for p in m.parameters() if p.requires_grad]
) / 1_000_000
print(f"Total params: {params:.2f}M, Trainable: {trainable_params:.2f}M")
return params, trainable_params
def trl_train():
wandb.login(key='replace_with_your_own')
lr = 2e-5
batch_size = 8
max_steps = 4
# evaluate every eval_steps. so if we set max_steps = 4 and
# eval_steps = 2, we will evaluate twice during training
eval_steps = 2
num_eval_data = 5
num_wandb_cb_eval_data = 7
wandb_cb_max_new_tokens = 256
num_train_epochs = 1
max_seq_length = 1024
gradient_accumulation_steps = 1
gradient_checkpointing = False
output_dir = "./output/"
run = wandb.init(
project="second_project",
config={
"lr": lr,
"batch_size": batch_size,
"max_steps": max_steps,
"eval_steps": eval_steps,
"num_eval_data": num_eval_data,
"num_wandb_cb_eval_data": num_wandb_cb_eval_data,
},
)
alpaca_ds = load_dataset("winglian/alpaca-gpt4-split")
train_dataset = alpaca_ds["train"]
eval_dataset = alpaca_ds["test"]
model_id = 'meta-llama/Llama-2-7b-hf'
# try different ways to initialize a llama model
# method 1: construct LLamaModel from LlamaConfig
# https://huggingface.co/docs/transformers/v4.37.2/en/model_doc
# /llama2#transformers.LlamaConfig
# configuration = LlamaConfig(
# num_hidden_layers=2,
# hidden_size=32,
# intermediate_size=2,
# num_attention_heads=1,
# num_key_value_heads=1,
# )
# model = LlamaModel(configuration)
# param_count(model)
# method 2 & 3 need to wait for token approval
# https://huggingface.co/meta-llama/Llama-2-7b-hf
# method 2: load config first, tune down model size, then initialize the actual LLM
# https://discuss.huggingface.co/t/can-i-pretrain-llama-from
# -scratch/37821/8
config = AutoConfig.from_pretrained(model_id)
config.num_hidden_layers = 1
config.hidden_size = 2
config.intermediate_size = 2
config.num_attention_heads = 1
config.num_key_value_heads = 1
model = AutoModelForCausalLM.from_config(config)
param_count(model)
# method 3: directly load pretrained llama model, which may encounter OOM
# on a consumer cpu machine
# model = AutoModelForCausalLM.from_pretrained(
# model_id,
# device_map="auto",
# trust_remote_code=True,
# low_cpu_mem_usage=True,
# torch_dtype=torch.bfloat16,
# load_in_8bit=True,
# )
training_args = TrainingArguments(
output_dir=output_dir,
use_cpu=True,
report_to="wandb",
per_device_train_batch_size=batch_size,
bf16=True,
learning_rate=lr,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
max_steps=max_steps,
eval_steps=eval_steps,
num_train_epochs=num_train_epochs,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=gradient_checkpointing,
gradient_checkpointing_kwargs={"use_reentrant": False},
evaluation_strategy="steps",
# logging strategies
logging_strategy="steps",
logging_steps=1,
save_strategy="no",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
trainer = SFTTrainer(
model,
tokenizer=tokenizer,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset.select(list(range(num_eval_data))),
# this tells the trainer to pack sequences of `max_seq_length`
# see illustration in https://wandb.ai/capecape/alpaca_ft/reports/How
# -to-Fine-tune-an-LLM-Part-3-The-HuggingFace-Trainer--Vmlldzo1OTEyNjMy
packing=True,
max_seq_length=max_seq_length,
formatting_func=create_alpaca_prompt,
compute_metrics=token_accuracy, # only call at evaluation
)
wandb_callback = LLMSampleCB(
trainer, eval_dataset,
num_samples=num_wandb_cb_eval_data,
max_new_tokens=wandb_cb_max_new_tokens,
)
trainer.add_callback(wandb_callback)
trainer.train()
wandb.finish()
# other materials:
# fine tune ppo vs dpo
# trl stackllama tutorial:
# https://huggingface.co/docs/trl/using_llama_models
# trl readme: https://github.com/huggingface/trl/tree/main?tab=readme-ov
# dpo - trl: https://huggingface.co/blog/dpo-trl
if __name__ == '__main__':
trl_train()
Now let’s examine the code in more details:
First, we initialize a weights & bias project (wandb.init(...)), which is used for logging intermediate training/evaluation results. It is a very convenient tool for logging and visualization.
Then, we use load_dataset(...) , an api from HuggingFace’s dataset library, to load a specific data. HuggingFace hosts many awesome datasets at https://huggingface.co/datasets.
Next, we initialize an actual LLM. Since this is a minimal example, I created a tiny LLM by modifying its config to have very few hidden layers and hidden sizes.
Next, we initialize TrainingArguments. We may need to be familiar with several concepts in TrainingArguments, such as gradient accumulation.
We then initialize a tokenizer, which is trivial by calling HuggingFace’s API AutoTokenizer.from_pretrained(...).
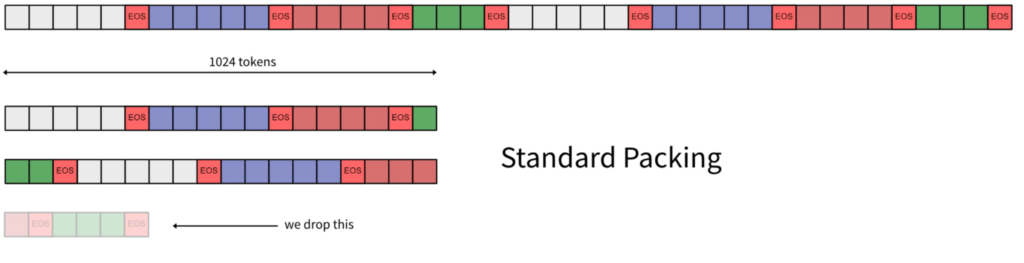
We then initialize SFTTrainer, the main class for training and evaluating the LLM. Setting packing=True means that we pack multiple individual sequences into a fixed-length sequence so that we can avoid much padding. Individual sequences are usually separated with an eos token.
We also initialize a callback, which is called only in the evaluation stage. The callback class needs to first remove output in the dataset for evaluation.
We now look at the results logged in wandb (example https://wandb.ai/czxttkl/third_project/runs/hinck0h5):
- Since we specify
max_steps=4 and eval_steps=2, we have 2 evaluations. The evaluation loss curves verifie we indeed log 2 evaluation results.

- we have a table showing the results from the callback. We can verify that prompts indeed have outputs removed. We can also use
runs.history.concat["sample_predictions"] instead of runs.summary["sample_predictions"] to check the evaluation results from all evaluation runs (exactly 2 runs) (see the reference in https://wandb.ai/morg/append-to-table/reports/Append-to-Table–Vmlldzo0MjY0MDIx)


![\max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}[r_\phi(x,y)] - \beta \mathbb{D}_{KL}[\pi_\theta(y|x) || \pi_{ref}(y|x)],](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-240b38196767f08289ae9f30402a4127_l3.png "Rendered by QuickLaTeX.com")
 but also, in balance, to minimize the KL-divergence from a reference policy
but also, in balance, to minimize the KL-divergence from a reference policy  .
. ![\mathbb{D}_{KL}[\pi_\theta(y|x) || \pi_{ref}(y|x)]=\sum_y \pi_\theta(y|x) \log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)} =\mathbb{E}_{y\sim \pi_\theta(y|x)}[\log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)}]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-5ebf661034347ef1a26ee6ad1aea9464_l3.png "Rendered by QuickLaTeX.com") , we have
, we have![\max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[r_\phi(x,y) - \beta (\log \pi_\theta(y|x) - \log \pi_{ref}(y|x)) \right] \newline = \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[r_\phi(x,y) + \beta \log \pi_{ref}(y|x) - \beta \log \pi_\theta(y|x) \right] \newline \text{because }-\log \pi_\theta(y|x) \text{ is an unbiased estimator of entropy } H(\pi_\theta)=-\sum_y \pi_\theta(y|x) \log \pi_\theta(y|x), \newline \text{we can transform to equation 2 in [3]} \newline= \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[r_\phi(x,y) + \beta \log \pi_{ref}(y|x) + \beta H(\pi_\theta)\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-1a11fbab8aaa1b5bf9f38c594342bcdc_l3.png "Rendered by QuickLaTeX.com")

 ; if X and Y are d-separated, then X and Y are independent given Z, denoted as
; if X and Y are d-separated, then X and Y are independent given Z, denoted as  . If two nodes are not d-connected, then they are d-separated. There are several rules for determining whether two nodes are d-connected or d-separated [3]. An interesting (and often non-intuitive) example is that in a v-structure like (X3, X4, X5) above: X3 is d-connected (i.e., dependent) to X4 given X5 (i.e., the collider), even though X3 and X4 has no direct edge in between [4].
. If two nodes are not d-connected, then they are d-separated. There are several rules for determining whether two nodes are d-connected or d-separated [3]. An interesting (and often non-intuitive) example is that in a v-structure like (X3, X4, X5) above: X3 is d-connected (i.e., dependent) to X4 given X5 (i.e., the collider), even though X3 and X4 has no direct edge in between [4].
 . When
. When  , the conditional independence test will return us
, the conditional independence test will return us  . Therefore, the identified conditional independence relationship from the data is not entailed by the FCM.
. Therefore, the identified conditional independence relationship from the data is not entailed by the FCM.![X_i = \sum\limits_k \alpha_k P_a^k(X_i)+E_i, \;\; i \in [1, N]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-175e512cfb74f88cb005d0dd0d358d15_l3.png "Rendered by QuickLaTeX.com")

 is not a linear model with Gaussian input and Gaussian noise
is not a linear model with Gaussian input and Gaussian noise
 , we penalize the unfavored output
, we penalize the unfavored output  with a hinge loss:
with a hinge loss:
 (the initial policy is denoted as
(the initial policy is denoted as 
 and lower the likelihood of losing responses
and lower the likelihood of losing responses  under a Bradley-Terry model.
under a Bradley-Terry model. To help understand more, you can see that the
To help understand more, you can see that the 





 , the forward process adds a Gaussian noise
, the forward process adds a Gaussian noise  in
in  steps until
steps until  is (or approximately close to) an isotropic Gaussian. The backward process tries to recover
is (or approximately close to) an isotropic Gaussian. The backward process tries to recover  from
from  with the probability
with the probability  . The eventual goal is that, given a training sample, we want
. The eventual goal is that, given a training sample, we want  to be as high as possible, where
to be as high as possible, where  . It turns out that maximizing
. It turns out that maximizing  be as close as possible to the distribution
be as close as possible to the distribution  . Because in the forward process we have recorded
. Because in the forward process we have recorded  ,
,  by fitting
by fitting 
 under a diffusion model
under a diffusion model  . Similar to
. Similar to ![\begin{equation*} \begin{split} & maximize \;\; \log p_\theta(x_0) \\ & \geq \log p_\theta(x_0) - \underbrace{D_{KL}\left( q\left( \mathbf{x}_{1:T} | \mathbf{x}_0 \right) || p_\theta\left( \mathbf{x}_{1:T} | \mathbf{x}_0 \right) \right)}_\text{KL divergence is non-negative} \\ &=\log p_\theta(x_0) - \mathbb{E}_{x_{1:T} \sim q(x_{1:T}|x_0) } \left[ \log \underbrace{\frac{q\left(\mathbf{x}_{1:T}|\mathbf{x}_0 \right)}{p_\theta\left( \mathbf{x}_{0:T}\right) / p_\theta \left( \mathbf{x}_0\right)}}_\text{Eqvlt. to $p_\theta\left( \mathbf{x}_{1:T} | \mathbf{x}_0 \right)$} \right] \\ &=\log p_\theta(x_0) - \mathbb{E}_{x_{1:T} \sim q(x_{1:T}|x_0) } \left[ \log \frac{q\left( \mathbf{x}_{1:T} | \mathbf{x}_0 \right)}{p_\theta \left( \mathbf{x}_{0:T}\right) } + \log p_\theta\left(\mathbf{x}_0 \right) \right] \\ &=- \mathbb{E}_{x_{1:T} \sim q(x_{1:T}|x_0) } \left[ \log \frac{q\left(\mathbf{x}_{1:T} | \mathbf{x}_0\right) }{p_\theta\left( \mathbf{x}_{0:T}\right)} \right] \\ &=-\mathbb{E}_{q}\biggl[ \\ &\quad \underbrace{D_{KL}\left( q( \mathbf{x}_T | \mathbf{x}_0) || p_\theta(\mathbf{x}_T) \right)}_\text{$L_T$} \\ &\quad + \sum\limits_{t=2}^T \underbrace{D_{KL}\left( q(\mathbf{x}_{t-1} | \mathbf{x}_t, \mathbf{x}_0) || p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) \right)}_\text{$L_{t-1}$} \\ &\quad \underbrace{- \log p_\theta(\mathbf{x}_0 | \mathbf{x}_1)}_\text{$L_{0}$} \\ &\biggr] \end{split} \end{equation*}](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-a6cb09750180f099f97c7db6eafeceaa_l3.png "Rendered by QuickLaTeX.com")
 for
for  because
because  is non-learnable and
is non-learnable and  is trivially handled. With some mathematical computation, we have
is trivially handled. With some mathematical computation, we have 

 ,
,  , and
, and  are terms involving noise scheduling steps
are terms involving noise scheduling steps  .
. , which can be parameterized as
, which can be parameterized as
![\mathrm{KL}[P\,||\,Q] = \frac{1}{2} \left[ (\mu_2 - \mu_1)^T \Sigma_2^{-1} (\mu_2 - \mu_1) + \mathrm{tr}(\Sigma_2^{-1} \Sigma_1) - \ln \frac{|\Sigma_1|}{|\Sigma_2|} - n \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-521cdfe1d097a186eb5421c808c1e3f3_l3.png "Rendered by QuickLaTeX.com") ,
,  ) can be expressed analytically and fed into autograd frameworks for optimization.
) can be expressed analytically and fed into autograd frameworks for optimization.