Introduction
In this post, we introduce one machine learning technique called stochastic variational inference that is widely used to estimate posterior distribution of Bayesian models. Suppose in a Bayesian model, the model parameters is denoted as a vector  and the observation is denoted as
and the observation is denoted as  . According to Bayesian theorem, the posterior distribution of can be computed as:
. According to Bayesian theorem, the posterior distribution of can be computed as:

 is the probability of observation marginal over all possible model parameters:
is the probability of observation marginal over all possible model parameters:

isn’t easy to compute, most of time intractable, because of its integral form. If we are not able to compute , then we are not able to compute  , which is what we want to know. Therefore, we need to come up with a way to approximate . We denote the approximated posterior as
, which is what we want to know. Therefore, we need to come up with a way to approximate . We denote the approximated posterior as  . is also called the variational distribution hence the name of variational inference.
. is also called the variational distribution hence the name of variational inference.
Stochastic variational inference (SVI) is such one method to approximate . From the ICML 2018 tutorial [2], we can see the niche where SVI lies: among all possible ways to approximate , there is a group of algorithms using optimization to minimize the difference between  and
and  . Those representing the difference between the two distributions as Kullback-Leibler divergence is called variational inference. If we further categorize based on the family of
. Those representing the difference between the two distributions as Kullback-Leibler divergence is called variational inference. If we further categorize based on the family of  , there is one particular family called mean-field variational family which is easy to apply variational inference. After all levels of categorization, we arrive at some form of objective function which we sort to minimize. SVI is one optimization method to optimize a defined objective function that pushes to reflect our interest in minimizing the KL-divergence with .
, there is one particular family called mean-field variational family which is easy to apply variational inference. After all levels of categorization, we arrive at some form of objective function which we sort to minimize. SVI is one optimization method to optimize a defined objective function that pushes to reflect our interest in minimizing the KL-divergence with .
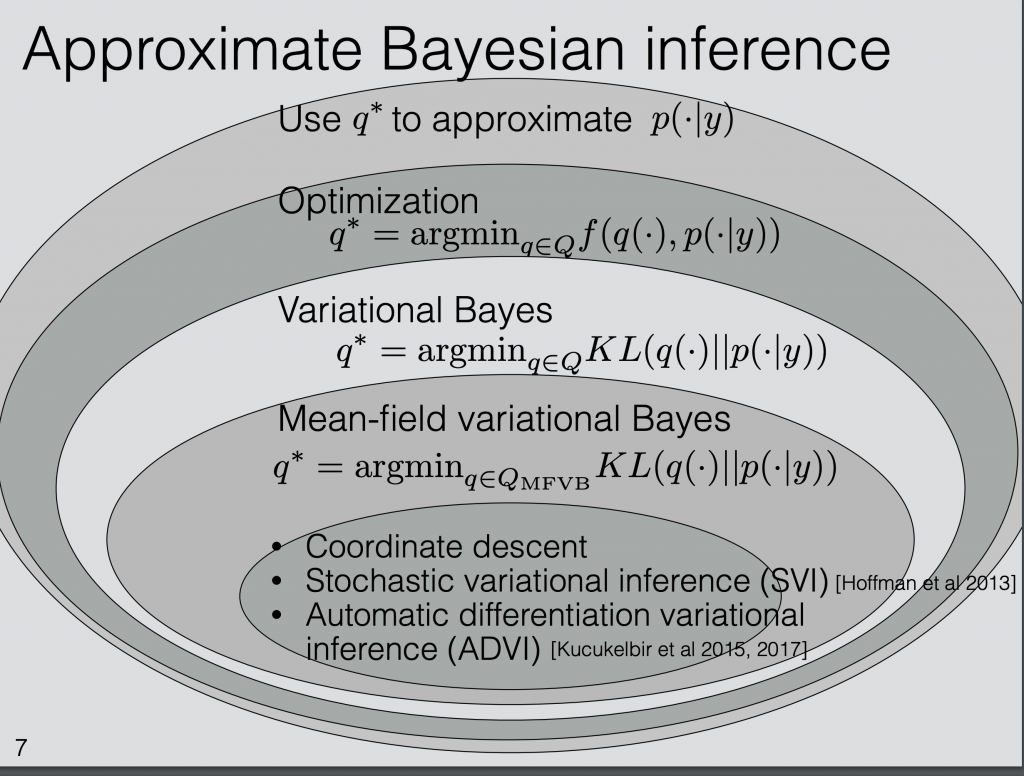
Objective function
By definition, KL divergence between two continuous distributions  and
and  is defined as [4]:
is defined as [4]:
![KL\left(h(x)||g(x)\right)\newline=\int^\infty_{-\infty}h(x)log\frac{h(x)}{g(x)}dx \newline=\mathbb{E}_h[log\;h(x)]-\mathbb{E}_h[log\;g(x)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-8501d9a8fd963ea67a6922b3315189d5_l3.png "Rendered by QuickLaTeX.com")
If we are trying to find the best approximated distribution  using variational Bayes, we define the following objective function:
using variational Bayes, we define the following objective function:
 ,
,
where ![KL(q(z)||p(z|x))=\mathbb{E}_q [log\;q(z)] - \mathbb{E}_q [log\;p(z,x)]+log\;p(x)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-20412537c9a69fb1219645c609aca19a_l3.png "Rendered by QuickLaTeX.com") . (all expectations are taken with respect to .) Note that if we are gonna optimize w.r.t
. (all expectations are taken with respect to .) Note that if we are gonna optimize w.r.t  , then
, then  can be treated as a constant. Thus, minimizing the KL-divergence is equivalent to maximizing:
can be treated as a constant. Thus, minimizing the KL-divergence is equivalent to maximizing:
![ELBO(q)=\mathbb{E}_q[log\;p(z,x)] - \mathbb{E}_q[log\;q(z)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-44dac15424746676e23c8c9dd88b3734_l3.png "Rendered by QuickLaTeX.com")
 is the lower bound of because of the non-negativity of KL-divergence:
is the lower bound of because of the non-negativity of KL-divergence:

Update 2020.4:
The derivation above is also illustrated in [14]:

There are several other ways to understand ELBO.
- Based on Jensen’s inequality [13]: for a convex function
 and a random variable
and a random variable  ,
, ![f(\mathbb{E}[X]) \leq \mathbb{E}\left[f(X)\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-600448c8beb2e15285d94f6085146d09_l3.png "Rendered by QuickLaTeX.com") ; for a concave function
; for a concave function  ,
, ![g(\mathbb{E}[X]) \geq \mathbb{E}\left[g(X)\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-b66abed9814432bc198369d55e5a7f25_l3.png "Rendered by QuickLaTeX.com") . Therefore, we have:
. Therefore, we have:
![log \; p(x)\newline=log \int_z p(z,x)\newline=log \int_z p(z,x)\frac{q(z)}{q(z)}\newline=log \int_z q(z)\frac{p(z,x)}{q(z)}\newline=log \left(\mathbb{E}_{q(z)}\left[\frac{p(z,x)}{q(z)}\right]\right) \newline \geq \mathbb{E}_{q(z)}\left[log \frac{p(z,x)}{q(z)}\right] \quad\quad \text{by Jensen's inequality} \newline =ELBO(q)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-24349341ab84453e6b667fde54e71db3_l3.png "Rendered by QuickLaTeX.com")
Therefore, is the lower bound of 
2. By rearranging , we have:
![ELBO(q)\newline=\mathbb{E}_q[log\;p(z,x)] - \mathbb{E}_q[log\;q(z)]\newline=\mathbb{E}_q[log\;p(x|z)] + \mathbb{E}_q[log\;p(z)] - \mathbb{E}_q[log\;q(z)] \quad\quad p(z) \text{ is the prior of } z \newline= \mathbb{E}_q[log\;p(x|z)] - \mathbb{E}_q [log \frac{q(z)}{p(z)}]\newline=\mathbb{E}_q[log\;p(x|z)] - KL\left(q(z) || p(z)\right)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-aa0eccc6fce4b2b3085999bb67659a1f_l3.png "Rendered by QuickLaTeX.com")
Therefore, the first part of can be thought as the so-called “reconstruction error”, which encourages to put more probability mass on the area with high  . The second part encourages to be close to the parameter prior
. The second part encourages to be close to the parameter prior  . is the common objective used in Variational Autoencoder models.
. is the common objective used in Variational Autoencoder models.
How to optimize?
Recall that our objective function is  . In practice, minimizing with regard to
. In practice, minimizing with regard to  translates to parameterize and then optimize the objective function with regard to the parameters. One big assumption we could make to facilitate computation is to assume all latent variables are independent such that can be factorized into the product of distributions of individual latent variables. We call such a the mean-field variational family:
translates to parameterize and then optimize the objective function with regard to the parameters. One big assumption we could make to facilitate computation is to assume all latent variables are independent such that can be factorized into the product of distributions of individual latent variables. We call such a the mean-field variational family:

From the factorization, you can see that each individual latent variable’s distribution is governed by its own parameter  . Hence, the objective function to approximate changes from to:
. Hence, the objective function to approximate changes from to:

One simple algorithm to optimize this is called coordinate ascent mean-field variational inference (CAVI). Each time, the algorithm optimizes one variational distribution parameter while holding all the others fixed. The algorithm works as follows:
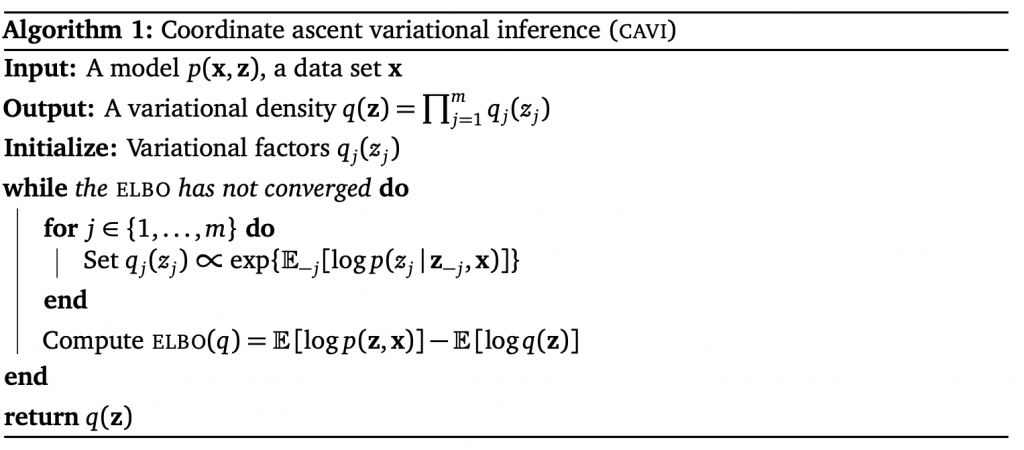
“Set ![q_j(z_j) \propto exp\{\mathbb{E}_{-j}[log p(z_j|z_{-j}, x)]\}](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-8363d2aec9de7b037c19991a7105feb8_l3.png "Rendered by QuickLaTeX.com") ” may seems hard to understand. It means that setting the variational distribution parameter such that
” may seems hard to understand. It means that setting the variational distribution parameter such that  follows the distribution that is equivalent to
follows the distribution that is equivalent to ![exp\{\mathbb{E}_{-j}[log p(z_j|z_{-j}, x)]\}](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-df13519a244296cb5ca9b9f499b32134_l3.png "Rendered by QuickLaTeX.com") up to a constant.
up to a constant.  means that the expectation is taken with regard to a distribution
means that the expectation is taken with regard to a distribution  .
.
What to do after knowing  ?
?
After the optimization (using CAVI for example), we get the variational distribution . We can use the estimated to analytically derive the mean of  or sample from
or sample from  . One thing to note is that there is no restriction on the parametric form of the individual variational distribution. For example, you may define to be an exponential distribution:
. One thing to note is that there is no restriction on the parametric form of the individual variational distribution. For example, you may define to be an exponential distribution:  . Then, the mean of is
. Then, the mean of is  . If is a normal distribution, then actually contains two parameters, the normal distribution’s mean and variance. Thus the mean of is simply the mean parameter.
. If is a normal distribution, then actually contains two parameters, the normal distribution’s mean and variance. Thus the mean of is simply the mean parameter.
Stochastic Variational Inference
One big disadvantage of CAVI is its scalability. Each update of requires full sweep of data to compute the update. Stochastic variational inference (SVI) kicks in because updates of using SVI only requires sub-samples of data. The simple idea is to take the gradient of  and use it to update
and use it to update  . But there is some more detail:
. But there is some more detail:
- formulas of updates would be very succinct if we assume complete conditionals are in the exponential family:
 , where is its own sufficient statistics,
, where is its own sufficient statistics,  ,
,  , and
, and  are defined according to the definition of the exponential family [10].
are defined according to the definition of the exponential family [10]. - We also categorize latent variables into local variables, and global variables.
- the gradient is not simply taken in the Euclidean space of parameters but in the distribution space [11]. In other words, the gradient is transformed in a sensible way such that it is in the steepest descent direction of KL-divergence. Also see [12].
All in all, SVI works as follows [8]:

Reference
[1] https://www.quora.com/Why-and-when-does-mean-field-variational-Bayes-underestimate-variance
[2] ICML 2018 Tutorial Session: Variational Bayes and Beyond: Bayesian Inference for Big Data: https://www.youtube.com/watch?time_continue=2081&v=DYRK0-_K2UU
[3] Variational Inference: A Review for Statisticians
[4] https://towardsdatascience.com/demystifying-kl-divergence-7ebe4317ee68
[5] https://www.zhihu.com/question/31032863
[6] https://blog.csdn.net/aws3217150/article/details/57072827
[7] http://krasserm.github.io/2018/04/03/variational-inference/
[8] NIPS 2016 Tutorial Variational Inference: Foundations and Modern Methods: https://www.youtube.com/watch?v=ogdv_6dbvVQ
[10] https://jwmi.github.io/BMS/chapter3-expfams-and-conjugacy.pdf
[11] https://wiseodd.github.io/techblog/2018/03/14/natural-gradient/
[12] https://czxttkl.com/2019/05/09/gradient-and-natural-gradient-fisher-information-matrix-and-hessian/