In this post, we are going to discuss one good idea from 2017 – information bottleneck [2]. Then we will discuss how the idea can be applied in meta-RL exploration [1].
Mutual Information
We will start warming up by revisiting a classic concept in information theory, mutual information [3]. Mutual information  measures the amount of information obtained about one random variable by observing the other random variable:
measures the amount of information obtained about one random variable by observing the other random variable: . From [3], we can see how these equations are derived:
. From [3], we can see how these equations are derived:

Stochastic Variational Inference and VAE
Stochastic variational inference (SVI) is a useful technique to approximate intractable posterior distribution. One good example is to use SVI for VAE. We have introduced SVI [4] and VAE [5] separately. In this post, we are going to explain both concepts again unifying the two concepts. A stackexchange post [7] also helped shape my writing.
Suppose we have data  and hypothesize data is generated by a latent process
and hypothesize data is generated by a latent process  , starting from a latent code
, starting from a latent code  .
.
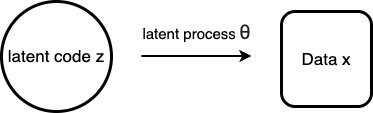
Then what we want to do is to maximize  , sometimes called the “log evidence”. Let
, sometimes called the “log evidence”. Let  to describe the posterior probability of given observing and
to describe the posterior probability of given observing and  to describe the joint probability of and . Note that, is infeasible to compute in general. Therefore, we introduce
to describe the joint probability of and . Note that, is infeasible to compute in general. Therefore, we introduce  to approximate , with
to approximate , with  being learnable parameters. is tractable, for example, a neural network with outputs representing a Gaussian distribution’s mean and variance but can only approximate the true posterior distribution, . It turns out that
being learnable parameters. is tractable, for example, a neural network with outputs representing a Gaussian distribution’s mean and variance but can only approximate the true posterior distribution, . It turns out that  can be rewritten into [see 6, page 22-23 for derivation]:
can be rewritten into [see 6, page 22-23 for derivation]: .
.
We call the second term,  , the evidence lower bound (ELBO). We have
, the evidence lower bound (ELBO). We have  because
because  . Therefore, we can maximize ELBO w.r.t. in order to maximize .
. Therefore, we can maximize ELBO w.r.t. in order to maximize .
ELBO can be further derived into [see derivation in 5]:![log p_\theta(x) \geq - KL\left(q_\phi(z|x) \Vert p_\theta(x, z)\right) = \newline \mathbb{E}_{z\sim q_\phi(z|x)}\left[ log p_\theta(x|z)\right] - KL\left( q_\phi(z|x) \Vert p(z) \right)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-c4e9ded405df8f5d13f8a29d89cb7445_l3.png "Rendered by QuickLaTeX.com") ,
,
where  is the prior for the latent code (e.g., standard normal distributions). In VAE, we also use a deterministic neural network to approximate
is the prior for the latent code (e.g., standard normal distributions). In VAE, we also use a deterministic neural network to approximate  . Overall,
. Overall, ![\mathbb{E}_{z\sim q_\phi(z|x)}\left[ log q_{\phi'}(x|z)\right] - KL\left( q_\phi(z|x) \Vert p(z) \right)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-6b189b2d079ea15bd219f14afeb9ab9a_l3.png "Rendered by QuickLaTeX.com") can be learned by minibatch samples and when ELBO is maximized, infinitely approximates .
can be learned by minibatch samples and when ELBO is maximized, infinitely approximates .
Deep Variational Information Bottleneck
If you view VAE as a clever idea to encode information of (data) in an unsupervised learning setting, Deep Variational Information Bottleneck [2] is an extended idea to encode latent information from (data) to  (label) in a supervised learning setting. The objective is to encode into latent code with as little mutual information as possible, while making preserve as much as possible mutual information with :
(label) in a supervised learning setting. The objective is to encode into latent code with as little mutual information as possible, while making preserve as much as possible mutual information with :

After some derivation shown in [2], we can show that we can also instead maximize a lower bound (notations slightly different than [2] because I want it to be consistent in this post):![I(z;y) - \beta I(z;x) \geq \mathbb{E}_{z\sim q_{\phi}(z|x)}\left[ log q_{\phi'}(y|z) \right]-\beta KL\left(q_\phi(z|x) \Vert p(z)\right),](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-7f01b74d310debf5d8608bfdb75f0a63_l3.png "Rendered by QuickLaTeX.com")
where, again, is the variational distribution to the true posterior distribution and  is the decoder network.
is the decoder network.
Meta-RL Exploration By a Deep Variational Information Bottleneck Method
With all necessary ingredients introduced, we now introduce how Meta-RL exploration can benefit from Information Bottleneck [1]. The basic Meta-RL setup is that we have diverse environments. Each environment is represented with a tensor (could be a one-hot encoding)  , which is known at training time but unknown at testing time. The authors of [1] propose to learn two policies:
, which is known at training time but unknown at testing time. The authors of [1] propose to learn two policies:  for exploring environments with the goal to collect as much information about the environment as possible, and
for exploring environments with the goal to collect as much information about the environment as possible, and  for exploiting an environment with a known encoded tensor . In training time,
for exploiting an environment with a known encoded tensor . In training time,  , an encoder to encode environment tensor
, an encoder to encode environment tensor  (available in training time) or
(available in training time) or  , a variational encoder which converts the trajectory generated by to an encoded tensor. The variational encoder
, a variational encoder which converts the trajectory generated by to an encoded tensor. The variational encoder  will be learned to match
will be learned to match  in training time. Once , ,
in training time. Once , ,  , and
, and  are learned, at testing time, we can run to collect trajectories
are learned, at testing time, we can run to collect trajectories  , use to determine the environment’s encoded tensor , and run on top to maximize rewards.
, use to determine the environment’s encoded tensor , and run on top to maximize rewards.
The paper uses the mutual information / deep variational information bottleneck ideas in two places. First, when we learn and , we use the following loss function to encourage encoding minimal information from :![\text{minimize} \qquad I(z;u) \newline \text{subject to} \quad \mathbb{E}_{z \sim F_{\psi}(z|\mu)}\left[ V^{\pi_\theta^{task}}(z;\mu)\right]=V^*(\mu) \text{ for all } \mu](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-d4f0b6a04603baee6f6cffcd0c405b09_l3.png "Rendered by QuickLaTeX.com")
The constrained optimization loss function can be converted to a unconstrained loss function by the lagrangian method, with  set as a hyperparameter [8]:
set as a hyperparameter [8]: ![\text{maximize}_{\psi, \theta}\quad \mathbb{E}_{\mu \sim p(\mu), z\sim F_{\psi}(z|\mu)}\left[V^{\pi_\theta^{task}}(z;\mu) \right] - \lambda I(z;\mu)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-14c643f47ee86cda0de04cd5656648fe_l3.png "Rendered by QuickLaTeX.com")
Using the same derivation from [2] (Eqn. 13 & 14), we know the lower bound of  is
is  , which has an analytic form when the prior is chosen properly (e.g., Gaussian). Thus the unconstrained loss function can be maximized on a lower bound.
, which has an analytic form when the prior is chosen properly (e.g., Gaussian). Thus the unconstrained loss function can be maximized on a lower bound.
Second, we encourage to maximize the mutual information between the trajectories explored by and  :
:![I(\tau^{exp};z) = H(z) - H(z|\tau^{exp}) \geq H(z) + \mathbb{E}_{\mu, z\sim F_\psi, \tau^{exp}\sim \pi^{exp}}\left[ q_\omega(z|\tau^{exp}) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-469e9c83627a52bb29fc69a25b776eb9_l3.png "Rendered by QuickLaTeX.com")
(The inequality uses the fact that the KL divergence between the true posterior distribution and the variational distribution,  , is greater than or equal to 0. )
, is greater than or equal to 0. )
As we see in the paper,  is learned to match , while, with some trick to rearrange
is learned to match , while, with some trick to rearrange ![\mathbb{E}_{\mu, z\sim F_\psi, \tau^{exp}\sim \pi^{exp}}\left[ q_\omega(z|\tau^{exp}) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-c5fa0e78a60ee5ee658bc9460e1d7145_l3.png "Rendered by QuickLaTeX.com") , we can optimize in an MDP with reward set as information gain of each step.
, we can optimize in an MDP with reward set as information gain of each step.
References
[1] Decoupling Exploration and Exploitation for Meta-Reinforcement Learning
without Sacrifices: https://arxiv.org/pdf/2008.02790
[2] DEEP VARIATIONAL INFORMATION BOTTLENECK: https://arxiv.org/pdf/1612.00410
[3] https://en.wikipedia.org/wiki/Mutual_information
[4] https://czxttkl.com/2019/05/04/stochastic-variational-inference/
[5] https://czxttkl.com/2020/04/06/optimization-with-discrete-random-variables/
[6] https://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2015/slides/lec12.vae.pdf
 , which is exactly the next token prediction distribution.
, which is exactly the next token prediction distribution.









 , is:
, is:![\max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}[r_\phi(x,y)] - \beta \mathbb{D}_{KL}[\pi_\theta(y|x) || \pi_{ref}(y|x)],](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-240b38196767f08289ae9f30402a4127_l3.png "Rendered by QuickLaTeX.com")
 but also, in balance, to minimize the KL-divergence from a reference policy
but also, in balance, to minimize the KL-divergence from a reference policy  .
. ![\mathbb{D}_{KL}[\pi_\theta(y|x) || \pi_{ref}(y|x)]=\sum_y \pi_\theta(y|x) \log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)} =\mathbb{E}_{y\sim \pi_\theta(y|x)}[\log\frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)}]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-5ebf661034347ef1a26ee6ad1aea9464_l3.png "Rendered by QuickLaTeX.com") , we have
, we have![\max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[r_\phi(x,y) - \beta (\log \pi_\theta(y|x) - \log \pi_{ref}(y|x)) \right] \newline = \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[r_\phi(x,y) + \beta \log \pi_{ref}(y|x) - \beta \log \pi_\theta(y|x) \right] \newline \text{because }-\log \pi_\theta(y|x) \text{ is an unbiased estimator of entropy } \mathcal{H}(\pi_\theta)=-\sum_y \pi_\theta(y|x) \log \pi_\theta(y|x), \newline \text{we can transform to equation 2 in [3]} \newline= \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[r_\phi(x,y) + \beta \log \pi_{ref}(y|x) + \beta \mathcal{H}(\pi_\theta)\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-a33dea15a8c89bf3260776df1cf4d7be_l3.png "Rendered by QuickLaTeX.com")
![\max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[r_\phi(x,y) - \beta (\log \pi_\theta(y|x) - \log \pi_{ref}(y|x)) \right] \newline = \min_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)} \left[ \log \frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)} - \frac{1}{\beta}r_\phi(x,y) \right] \newline =\min_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)} \left[ \log \frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)} - \log exp\left(\frac{1}{\beta}r_\phi(x,y)\right) \right] \newline = \min_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)} \left[ \log \frac{\pi_\theta(y|x)}{\pi_{ref}(y|x)exp\left(\frac{1}{\beta}r_\phi(x,y)\right)} \right] \newline \pi_{ref}(y|x)exp\left(\frac{1}{\beta}r_\phi(x,y)\right) \text{ may not be a valid distribution. But we can define a valid distribution:} \pi^*(y|x)=\frac{1}{Z(x)}\pi_{ref}(y|x)exp\left(\frac{1}{\beta}r_\phi(x,y)\right), \text{ where } Z(x) \text{ is a partition function not depending on } y \newline = \min_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)} \left[ \log \frac{\pi_\theta(y|x)}{\pi^*(y|x)} \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-abe10cca2808da4aaf2d3f96b11abd12_l3.png "Rendered by QuickLaTeX.com")
 everywhere.
everywhere.![\max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y\sim \pi_\theta(y|x)}\left[\underbrace{r_\phi(x,y) + \beta \log \pi_{ref}(y|x)}_{\text{actual reward function}} + \beta \mathcal{H}(\pi_\theta)\right] \newline s.t. \quad \sum\limits_y \pi_\theta(y|x)=1,](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-806a96f47b9f83798b88f60131252bf1_l3.png "Rendered by QuickLaTeX.com")
 . Note, we are solving a one-step MaxEnt RL problem. So we can use the Lagrangian multipliers method to reach the same solution. See 1hr:09min in [5] for more details.
. Note, we are solving a one-step MaxEnt RL problem. So we can use the Lagrangian multipliers method to reach the same solution. See 1hr:09min in [5] for more details.
 . With some arrangement, we can see that this formula entails that the reward function can be represented as a function of
. With some arrangement, we can see that this formula entails that the reward function can be represented as a function of  and
and 
 and a Bradley-Terry model, we know that
and a Bradley-Terry model, we know that 
 into the logit [7]:
into the logit [7]:
![-\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}\left[\log \sigma \left(r(x, y_w) - r(x, y_l)\right) \right] \newline = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}\left[ \log \sigma \left( \left(\beta \log \pi^*_\theta(y_w|x) - \beta \log \pi_{ref} (y_w | x) \right) - \left( \beta \log \pi^*_\theta(y_l |x) - \beta \log \pi_{ref} (y_l | x) \right)\right)\right] \newline = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}\left[ \log \sigma \left( \beta \log \frac{\pi^*_\theta(y_w|x)}{\pi_{ref} (y_w | x)} - \beta \log \frac{\pi^*_\theta(y_l |x)}{\pi_{ref} (y_l | x)} \right) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-f305d09d3d4969371cc4d16552d0e9fe_l3.png "Rendered by QuickLaTeX.com")

![-\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}\left[ \log \sigma \left( \beta \log \frac{\pi^*_\theta(y_w|x)}{\pi_{ref} (y_w | x)} - \beta \log \frac{\pi^*_\theta(y_l |x)}{\pi_{ref} (y_l | x)} \right) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-ff2bc73960aca346b8a20c8baa04e2f3_l3.png "Rendered by QuickLaTeX.com") , still align the underlying policy to the Bradley-Terry preference probability defined in the token-level MDP? The answer is yes as proved in [3]. We first need to make an interesting connection between the decoding process and multi-step Maximum Entropy RL. (Note, earlier in this post, we have made a connection between on-step Maximum Entropy RL and DPO in the setting of bandits.)
, still align the underlying policy to the Bradley-Terry preference probability defined in the token-level MDP? The answer is yes as proved in [3]. We first need to make an interesting connection between the decoding process and multi-step Maximum Entropy RL. (Note, earlier in this post, we have made a connection between on-step Maximum Entropy RL and DPO in the setting of bandits.) ![\pi^*_{MaxEnt} = \arg\max_\pi \sum_t \mathbb{E}_{(s_t, a_t) \sim \pho_\pi} \left[ r(s_t, a_t) + \beta \mathcal{H}\left(\pi(\cdot | s_t)\right)\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-4d58c569f6261979c4601a0f193caf00_l3.png "Rendered by QuickLaTeX.com") . People have proved the optimal policy can be derived as
. People have proved the optimal policy can be derived as  where
where  and
and  are the corresponding Q-function and V-function in the MaxEnt RL [8]. For any LLM, its decoding policy
are the corresponding Q-function and V-function in the MaxEnt RL [8]. For any LLM, its decoding policy  is a softmax over the whole vocabulary. Therefore,
is a softmax over the whole vocabulary. Therefore,  in terms of an LLM’s decoding process. We could re-arrange the formula to represent per-token reward as:
in terms of an LLM’s decoding process. We could re-arrange the formula to represent per-token reward as:

![-\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left(\beta \sum\limits_{i=1}^{N}\log \frac{\pi_\theta(y_w^i | x, y_{w, <i})}{\pi_{ref}(y_w^i | x, y_{w,<i})} - \beta \sum\limits_{i=1}^M \log \frac{\pi_\theta(y_l^i | x, y_{l, <i})}{\pi_{ref}(y_l^i | x, y_{l,<i})} \right) \right] \newline = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}}\left[ \log \sigma \left( \beta \log \frac{\pi^*_\theta(y_w|x)}{\pi_{ref} (y_w | x)} - \beta \log \frac{\pi^*_\theta(y_l |x)}{\pi_{ref} (y_l | x)} \right) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-982b48b23d236150e21ff1c8f0e9f051_l3.png "Rendered by QuickLaTeX.com")



 ; if X and Y are d-separated, then X and Y are independent given Z, denoted as
; if X and Y are d-separated, then X and Y are independent given Z, denoted as  . If two nodes are not d-connected, then they are d-separated. There are several rules for determining whether two nodes are d-connected or d-separated [3]. An interesting (and often non-intuitive) example is that in a v-structure like (X3, X4, X5) above: X3 is d-connected (i.e., dependent) to X4 given X5 (i.e., the collider), even though X3 and X4 has no direct edge in between [4].
. If two nodes are not d-connected, then they are d-separated. There are several rules for determining whether two nodes are d-connected or d-separated [3]. An interesting (and often non-intuitive) example is that in a v-structure like (X3, X4, X5) above: X3 is d-connected (i.e., dependent) to X4 given X5 (i.e., the collider), even though X3 and X4 has no direct edge in between [4].
 . When
. When  , the conditional independence test will return us
, the conditional independence test will return us  . Therefore, the identified conditional independence relationship from the data is not entailed by the FCM.
. Therefore, the identified conditional independence relationship from the data is not entailed by the FCM.![X_i = \sum\limits_k \alpha_k P_a^k(X_i)+E_i, \;\; i \in [1, N]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-175e512cfb74f88cb005d0dd0d358d15_l3.png "Rendered by QuickLaTeX.com")

 is not a linear model with Gaussian input and Gaussian noise
is not a linear model with Gaussian input and Gaussian noise
 , we penalize the unfavored output
, we penalize the unfavored output  with a hinge loss:
with a hinge loss:
 (the initial policy is denoted as
(the initial policy is denoted as 
 and lower the likelihood of losing responses
and lower the likelihood of losing responses  under a Bradley-Terry model.
under a Bradley-Terry model. To help understand more, you can see that the
To help understand more, you can see that the 



