This post is mainly about Gaussian kernel (aka radial basis function kernel), a commonly used technique in machine learning. We’ve touched the concept of Gaussian kernel in [1] and [2] but with less details.
Definition of Gaussian Kernel
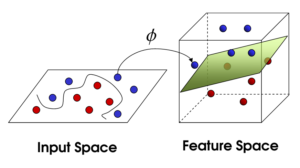
The intuitive understanding of a kernel is that it maps points in a data space, where those points may be difficult to be classified, to a higher dimensional space, where the corresponding mapped points are easier to be separable.
Gaussian kernel is defined as:
![\[K(\mathbf{x}, \mathbf{y})=exp\left(-\frac{\|\mathbf{x}-\mathbf{y}\|^2}{2\sigma^2}\right),\]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-b79b831a52476a21c48ca2567248e86f_l3.png "Rendered by QuickLaTeX.com")
where  and
and  are two arbitrary points in the data space,
are two arbitrary points in the data space,  is a hyperparameter of the Gaussian kernel that controls the sensitivity of difference when and are different. Imagine goes to infinity, then no matter how different and are,
is a hyperparameter of the Gaussian kernel that controls the sensitivity of difference when and are different. Imagine goes to infinity, then no matter how different and are,  will be 1. The formula of Gaussian kernel is identical to the PDF of a normal distribution.
will be 1. The formula of Gaussian kernel is identical to the PDF of a normal distribution.
can be understood as the distance between the corresponding points of and in the mapped higher dimensional space (denoted as  and
and  ). The higher dimensional space is actually an infinite dimensional space, and the distance is measured by the dot product. That is,
). The higher dimensional space is actually an infinite dimensional space, and the distance is measured by the dot product. That is,  .
.
So what is then? According to ([3] page 11), we have:

Application of Gaussian Kernels
Using Gaussian kernels, we can design classification/regression algorithms and their ideas would be similar to nearest neighbor algorithms. Here is how [4]. Suppose we have  data points
data points  with their labels
with their labels  . Each of the data points will contribute some information
. Each of the data points will contribute some information  to the prediction of a new data point
to the prediction of a new data point  .
.

Intuitively, those  that are close to should contribute more information; those that are far away from should contribute less information. Therefore, we use a Gaussian kernel
that are close to should contribute more information; those that are far away from should contribute less information. Therefore, we use a Gaussian kernel  to denote the degree of that should contribute to . This screenshot comes from [4], where
to denote the degree of that should contribute to . This screenshot comes from [4], where 
The way to learn is that we want  . Therefore, we can solve the following matrix-vector equation to obtain
. Therefore, we can solve the following matrix-vector equation to obtain  :
:

Once we have , we have full information of our regression/classification model , and we can use it to make prediction to unseen data.
We can use Gaussian kernel to perform smoothing. In [11], the author detailed some examples of applying Gaussian kernel for smoothing. In the example below, the authors generated some noisy data in 1D array (left). By applying a Gaussian kernel, that is averaging the values mostly from the neighborhood, we get a much smoother data distribution (right).
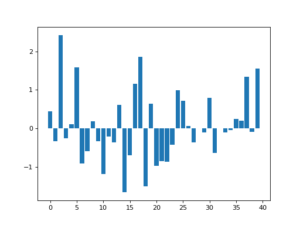
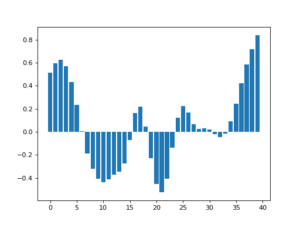
Magically, applying a correct Gaussian kernel can recover from noisy data that seems random. Below, we can see that a clean data distribution (up left), after added with noise (up right), can be recovered mostly if the Gaussian kernel “matches” certain characteristics of the noise (bottom).
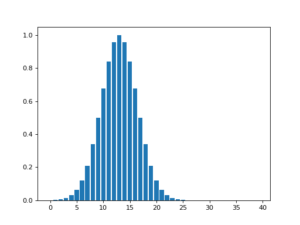

Another application of Gaussian kernels is to perform kernel density estimation [5]. It is a technique to depict a smooth probability distribution from finite data samples. The smoothness of the probability distribution is determined by the hyperparameter . When is small, the distribution will look like histograms because the kernel will average data on near neighbors. Larger will have wider focus on data.


Convolution and Fourier Transform
Gaussian kernels can be used in the setting of convolution and Fourier transform. We first quickly review what convolution and Fourier transform are and their relationships.
A convolution of two functions is defined as:
![\[f(t)=(g*h)(t)=\int^\infty_{-\infty}g(\tau)h(t-\tau)d\tau\]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-237cc2257376e03764228a073433bafd_l3.png "Rendered by QuickLaTeX.com")
For a function that is on the time domain  , its frequency domain function
, its frequency domain function  is defined as:
is defined as:
![\[\hat{f}(\xi)=\int^{\infty}_{-\infty}f(t)e^{-2\pi i t \xi} dt\]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-bdcf4fbf82c13fb6b7e8c2a58a4ae12d_l3.png "Rendered by QuickLaTeX.com")
And the inverse Fourier transform is defined as:
![\[f(t)=\int^\infty_{-\infty}\hat{f}(\xi)e^{2\pi i t \xi} d\xi\]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-1c2eeeb000305a965a637e37ca7f52a0_l3.png "Rendered by QuickLaTeX.com")
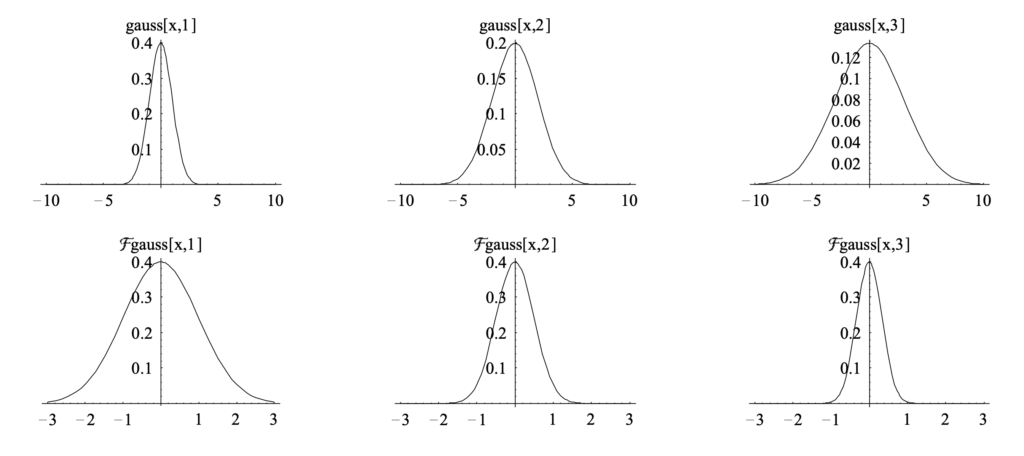
If itself is a Gaussian function, then would also be a Gaussian function but with different shapes. The more spread is, the sharper is [9]. This means, a spread changes slowly so it has less high-frequency components.
Now let’s prove the convolution theorem, which states that the Fourier transform of the convolution of two functions is equal to the product of the Fourier transform of each function. The proof comes from the last page of [10]:
Suppose we have  , and suppose ,
, and suppose ,  , and
, and  are the corresponding Fourier transformed functions. From the inverse Fourier transform we have
are the corresponding Fourier transformed functions. From the inverse Fourier transform we have  and
and  .
.
By the definition of convolution:
![(g*h)(t)=\int^\infty_{-\infty}g(\tau)h(t-\tau)d\tau \newline=\int^\infty_{-\infty} g(\tau)\left[\int^\infty_{-\infty} \hat{h}(\xi) 2^{\pi i (t-\tau) \xi}d\xi\right]d\tau \newline=\int^\infty_{-\infty} \hat{h}(\xi) \left[\int^\infty_{-\infty} g(\tau) 2^{\pi i (t-\tau) \xi}d\xi\right]d\tau \quad \quad \text{swap } g(\tau)\text{ and }\hat{h}(\xi)\newline=\int^\infty_{-\infty} \hat{h}(\xi) \left[\int^\infty_{-\infty} g(\tau) 2^{-\pi i \tau \xi} d\tau\right] 2^{\pi i t \xi} d\xi\newline=\int^\infty_{-\infty} \hat{h}(\xi) \hat{g}(\xi) 2^{\pi i t \xi} d\xi \newline = IFT\left[\hat{h}(\xi) \hat{g}(\xi)\right] \quad\quad Q.E.D.](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-1771258be13b140b77c42f636647fb99_l3.png "Rendered by QuickLaTeX.com")
I think [6] summarizes well the relationship between convolution and Fourier Transform [7].


Now let’s understand the last sentence from the last slide: convolution with a Gaussian will preserve low-frequency components while reducing high-frequency components.
Suppose we have a rectangle function  with width 2 and height 1.
with width 2 and height 1. 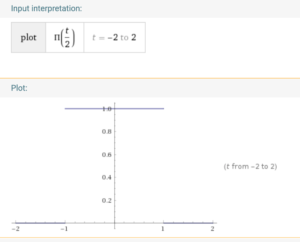 We know that its fourier transform is (https://www.wolframalpha.com/input/?i=+rect%28t%2F2%29+from+-2+to+2):
We know that its fourier transform is (https://www.wolframalpha.com/input/?i=+rect%28t%2F2%29+from+-2+to+2):

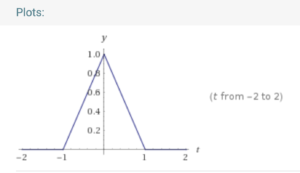
After applying Gaussian kernel smoothing (e.g.,  , as we introduced in the application section, we probably get a smoother function roughly like a triangle function
, as we introduced in the application section, we probably get a smoother function roughly like a triangle function  (https://www.wolframalpha.com/input/?i=triangle%28t%29):
(https://www.wolframalpha.com/input/?i=triangle%28t%29):
 ‘s fourier transform is (https://www.wolframalpha.com/input/?i=fourier+transform+%28triangle%28t%29%29):
‘s fourier transform is (https://www.wolframalpha.com/input/?i=fourier+transform+%28triangle%28t%29%29):
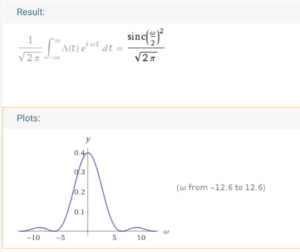
Apparently, we can see that the high frequency components of is much smaller than those of  .
.
![]()
From the point of the convolution theorem to understand this phenomenon, the fourier transform of  is equal to
is equal to  . We know that is a
. We know that is a  function and is a gaussian function, therefore the high frequency components of
function and is a gaussian function, therefore the high frequency components of  would be attenuated.
would be attenuated.
References
[1] https://czxttkl.com/2018/01/20/my-understanding-in-bayesian-optimization/
[2] https://czxttkl.com/2017/12/28/revisit-support-vector-machine/
[3] https://www.csie.ntu.edu.tw/~cjlin/talks/kuleuven_svm.pdf
[4] https://www.youtube.com/watch?v=O8CfrnOPtLc
[5] http://www.surajrampure.com/resources/ds100/KDE.html
[6] https://web.stanford.edu/class/cs279/lectures/lecture9.pdf
[7] https://czxttkl.com/2018/10/07/eulers-formula/
[8] https://en.wikipedia.org/wiki/Fourier_transform#Other_conventions
[9] http://pages.stat.wisc.edu/~mchung/teaching/MIA/reading/diffusion.gaussian.kernel.pdf.pdf
[10] http://ugastro.berkeley.edu/infrared09/PDF-2009/convolution2.pdf
[11] https://matthew-brett.github.io/teaching/smoothing_intro.html