There are many advancements in new model architectures in AI domain. Let me overview these advancements in this post.
Linear Compression Embedding
LCE [1] is simply using a matrix to project one embedding matrix to another:  , where
, where  .
.
Pyramid networks, inception network, dhen, lce
Perceiver and Perceiver IO
Perceiver-based architectures [5,6] solve a pain point of traditional transformers: quadratic computation in terms of sequence length for computing KQV attention, where K/Q/V all have the shape batch_size x seq_len x emb_dim. Perceiver-based architectures creates a learnable V matrix which is independent of input sequence lengths, thus to reduce the attention computation to be linear. Thanks to linear attention computation time, within the same computation budget, it is also able to stack more attention blocks to improve the performance. There are three web tutorials that are helpful: [3,4,5].
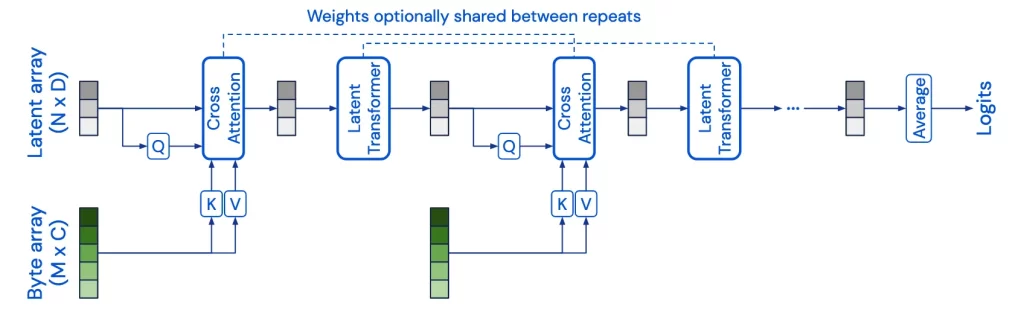
Since Perceiver has done a good job of reducing attention computation to linear time (in terms of sequence length), I was wonder why recent LLMs did not, if any, adopt this architecture. A reddit online discussion shed some light [7].
Mamba
Mamba [9] is a new sequence modeling architecture which also achieves linear time based on so called “selective structured state space model”. Currently, it achieves SOTA in many tasks. The official implementation can be found here. There is not much material which can clearly articulate the theory behind Mamba. I have only found pieces of information here and there: [8, 10]. The way I understand about Mamba after watching [8] is:
- Mamba enjoys the best of both worlds of RNN and Transformers
Training Inference RNN O(N) but can’t be parallelized because states need to roll out sequentially O(1) per token Transformer O(N^2) but can be parallelized O(N) per token (see time analysis in [12]) Mamba O(N) and can be parallelized O(1) per token - According to basic definition of structured state space sequence (S4) models [10], Mamba has the state transition represented as differential equations:


Note, is the change (i.e., derivative) of the hidden state.
is the change (i.e., derivative) of the hidden state. - The differential equations describe a real-time system but in sequence modeling we are interested in sequences with discrete time steps (i.e., tokens). “Discretization” in the paper means that we use approximation methods to derive new matrices
 and
and  when we assume the input function
when we assume the input function  becomes the sequence
becomes the sequence  , where
, where  is the step size.
is the step size.
There are two methods to do the discretization. [8] introduces the Euler’s method, which is simple for exposition. The paper uses zero-order hold, which is explained in more details in [13]. We use the Euler’s method for illustration, following [8]:- by definition of derivative we know that

- Substitute the state space model’s equations with step 1:

- by definition of derivative we know that
- State transitions during training can be parallelized without needing to wait for sequential rollout because the state transition model can be converted into convolutional formulation that only depends on the input sequences:

- A S4 mdoel is used for one input dimension. So if a token has 512 embedding size, there will be 512 S4 models in parallel. In comparison, transformers use attention heads where each attention head consumes all dimensions (or a group of dimensions) of a token.

Reference
- LCE explanation: https://fb.workplace.com/groups/watchrankingexperiments/permalink/2853044271454166/ (internal) and https://www.dropbox.com/scl/fi/0ygejam1mg2jhocfmgoba/watch-_-chaining-ranking-experiment-review-_-group-_-workplace.pdf?rlkey=4euhhg6f0h838ythg1na1amz8&dl=0 (external)
- https://medium.com/@curttigges/the-annotated-perceiver-74752113eefb
- https://medium.com/ml-summaries/perceiver-paper-s-summary-3c589ec74238
- https://medium.com/ml-summaries/perceiver-io-paper-summary-e8f28e451d21
- Perceiver: General Perception with Iterative Attention: https://arxiv.org/abs/2103.03206
- Perceiver IO: A General Architecture for Structured Inputs & Outputs: https://arxiv.org/abs/2107.14795
- https://www.reddit.com/r/MachineLearning/comments/tx7e34/d_why_arent_new_llms_using_the_perceiver/
- https://www.youtube.com/watch?v=8Q_tqwpTpVU
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces: https://arxiv.org/abs/2312.00752
- https://srush.github.io/annotated-s4/?ref=blog.oxen.ai
- https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad
- Llama code anatomy: https://czxttkl.com/2024/01/17/llama-code-anatomy/
- https://en.wikipedia.org/wiki/Discretization#Derivation