7 years ago I posted one tutorial about recommendation systems. Now it is 2022 and there are many more advancements. This post will overview several latest ideas.
CTR models
Google’s recsys 2022 paper [1] introduces many practical details on their CTR models. First, to reduce training cost, there are 3 effective ways: applying bottleneck layers (a layer’s weight matrix can be broken down into two low-rank matrices), weight-sharing neural architecture search, and data sampling. The contribution to training cost decrease of the 3 techniques is listed below. It seems like data sampling is a very effective technique.
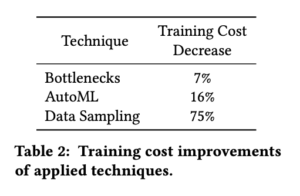
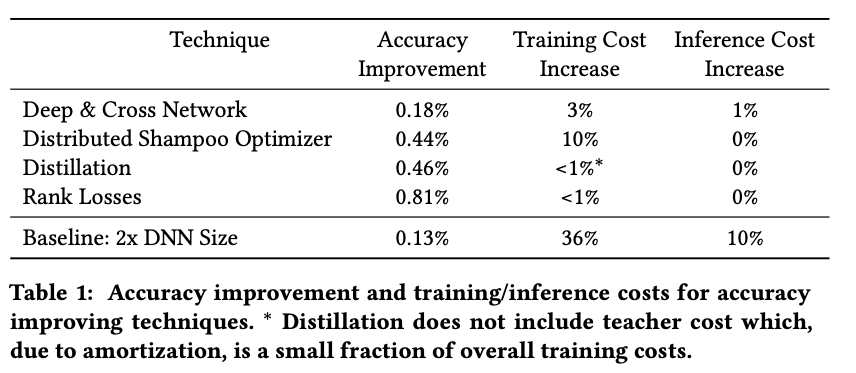
Second, to improve the model performance, they include the rank loss (pairwise ranking loss) to the pointwise cross entropy training loss, distillation, second-order optimizer, and add so-called deep&cross network to learn feature interaction. The contribution of these techniques to the accuracy is listed below:
Graph models
Let’s look at Pixie, Pinterest’s real-time random walk system for recommending pins [2]. The graph in this paper has pins and boards (a collection of pins of similar topics) as nodes. If a user has saved pin p in board b, then there is an edge between node p and b. Given a query pin, we can use random walk to surface more connected pins on the graph. Random walk’s idea has been introduced in one previous post.
Pixie has several customizations on random walk to boost its business value. First, it biases random walk on user-relevant nodes (e.g., favoring pins of the same language as the user is predicted to know). Second, they allocate the number of random walk steps based on a specific formula (Eqn. 2). They claim “the distribution gave us the desired property that more steps are allocated to starting pins with high degrees and pins with low degrees also receive sufficient number of steps”. Third, they boost pins that are reached from multiple pins, which indicates the pins are more relevant than others. Fourth, they apply early stopping and graph pruning to make random walk more efficient.
Interestingly, we can see that Pinterest loads the graph in single machines so that random walk can happen without cross-machine communication:

Retrieval
PinnerSage outlines a solution for retrieving related pins at Pinterest. The most interesting part is that PinnerSage learns a fluid number of user embeddings per user. So the retrieval would not have to be constrained to only the pins around the “mean” user preference.
PinnerSage uses pre-trained embeddings for each watched pins and cluster each user’s past 90 days watched pins into a dynamic number of clusters. The clustering method which supports an automatic determination of the number of clusters is called Ward. The user’s embeddings are the medoid of his/her clusters. PinnerSage also computes the importance of each cluster. The importance score will be used in the serving time as only the top 3 most important clusters’ user embeddings are used for retrieving new pins. The serving uses a typical approximated KNN searcher to retrieve new pins. The paper tried several common AKNN indexing schemes (LSH Orthoplex, Product Quantization, and HNSW) and found HNSW performed best on cost, latency, and recall.
Sequence Modeling
User history has abundant information about user preference. PinnerFormer [4] details an industrial sequence model used at Pinterest. User history is represented as pin sequences. Passing pin sequences through a transformer will generate an embedding per position. The loss function (named Dense All Action Loss) is defined as to predict each pin’s future positive engaged pins.
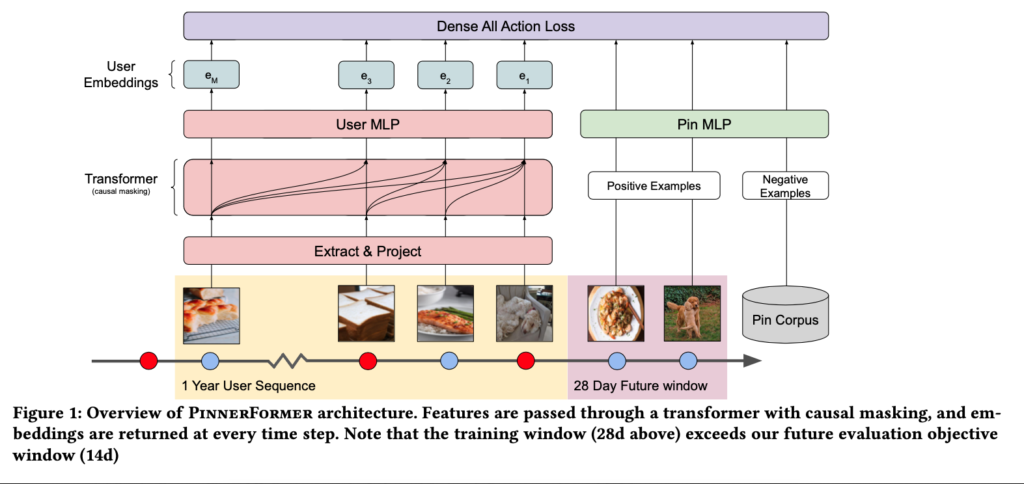
For model serving, the paper described that there is a daily workflow which updates the embeddings of users who have any type of engagement in the past day. Inactive users in the past day will keep using the previously generated embeddings. However, this also indicated the transformer model is not updated frequently otherwise all user embeddings need to be updated as the transformer model is updated.
There are several earlier sequence modeling works:
- Deep Interest Network [6]. In essence, DIN is a pioneer work for learning attentions between the current ad and all previous ads. Attention scores can be understood as the intensity of user interests between ads. The only difference between DIN and other attention-based models is that attention scores are allowed to sum up to not exactly 1 (see their explanation in section 4.3).
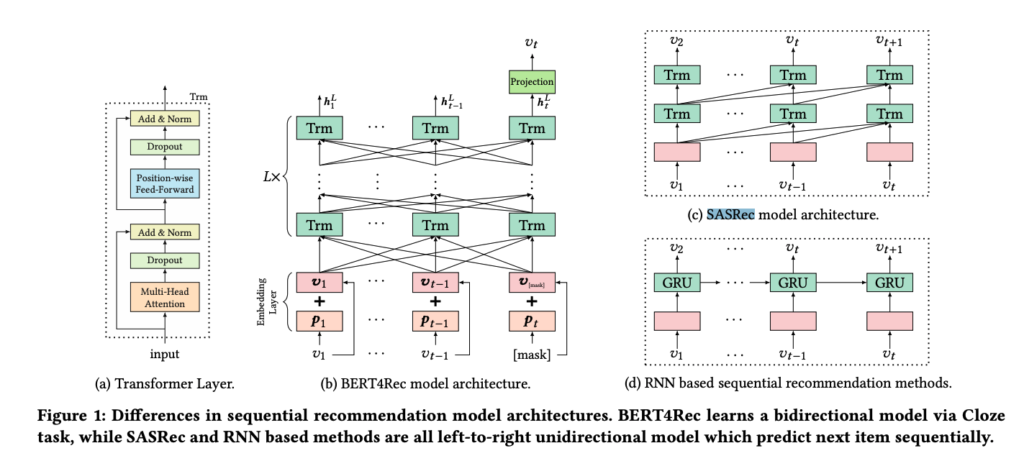
- Bert4Rec [7]. Vanilla sequential recommendation models, like vanilla Transformers / RNN-based models as referenced in [7], run through items from left to right and predict next items sequentially. Therefore, vanilla sequential recommendation models are considered as “unidirectional”. Bert4Rec applies bidirectional transformers models to learn inter-relationships between items. It introduces a task called Cloze task as the objective function. Basically, they randomly remove some items in input sequences (i.e., replace them with a special token “[mask]”) and then predict the ids of the masked items based on their surrounding context.

On device
Alibaba published EdgeRec [5] which can process fine-grain user events in real time and perform contextual reranking. They categorize user events into two types: item exposure actions and item page-view actions. Item exposure actions depict user scroll behavior and exposing duration while item page-view actions depict more engaged behavior like “add to cart” or “click customer service”. As you can guess, item page-view actions are much more sparse than item exposure actions. Therefore, EdgeRec decides to process the two types of actions as two separate sequences. EdgeRec uses GRUs to process the two sequences and generate a hidden representation for each action. At the re-ranking stage, each candidate has a re-ranking representation which comes from (1) the context of other candidates and (2) attention to the item exposure and item page-view action sequences. The context of other candidates is generated by another GRU which runs through the candidates in the order generated by the previous ranker. The re-ranking representation is then passed through a multi-layer perceptron (MLP) and finally the cross-entropy loss for learning.
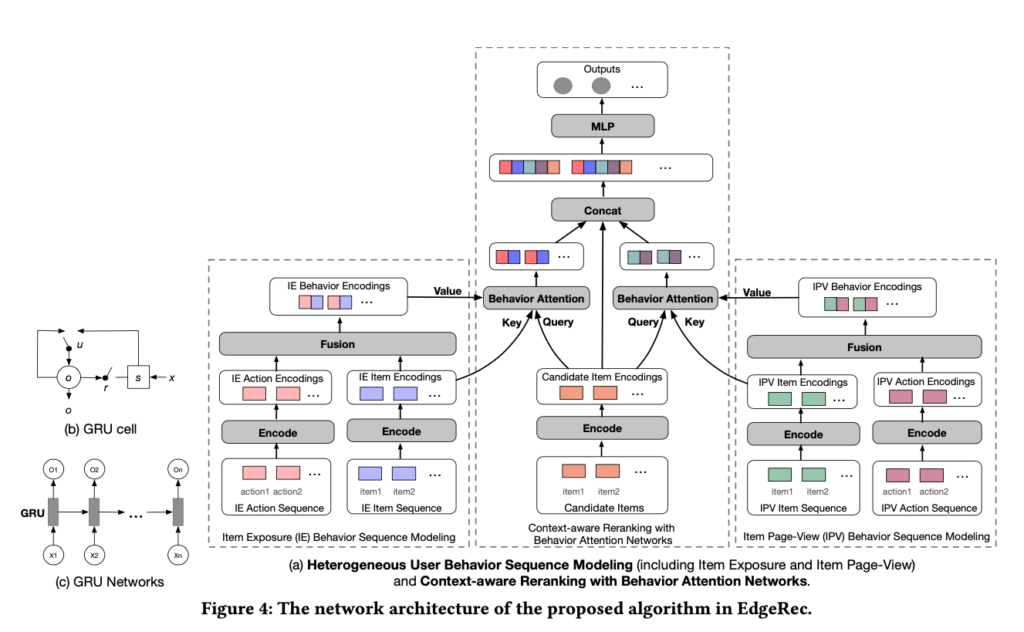
It is important to pay attention to the serving details of EdgeRec (section 2.2.2). First, although the whole EdgeRec model is trained, the GRUs for processing action sequences and the GRU for re-ranking are separately run on device during serving. The GRUs for processing action sequences will run for each new incoming user action (O(1) time complexity as claimed in the paper) on device and store generated embeddings in a database on device. The re-ranking GRU will fetch the generated embeddings from the on-device database and then perform model inference based on them. Another engineering detail is that since the model may use sparse features and their corresponding embedding tables may have high cardinality, they have to store embedding tables on cloud and send only relevant rows to device. There is also some versioning engineering details which ensure the edge and cloud’s models and embedding tables can match with each other.
References
[1] On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models: https://arxiv.org/abs/2209.05310
[2] Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time: https://arxiv.org/abs/1711.07601
[3] PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest: https://arxiv.org/abs/2007.03634
[4] PinnerFormer- Sequence Modeling for User Representation at Pinterest: https://arxiv.org/abs/2205.04507
[5] EdgeRec: Recommender System on Edge in Mobile Taobao: https://arxiv.org/abs/2005.08416
[6] Deep Interest Network for Click-Through Rate Prediction: https://arxiv.org/abs/1706.06978
[7] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer: https://arxiv.org/pdf/1904.06690.pdf