I start to feel the importance of simulating any practical problem before deploying an RL policy. If you cannot implement a reasonable simulator on your own, you are not clear about your environment and your model. It is then a pure gamble to me if we just train an RL policy offline without testing in a reasonable simulator and go directly to online testing. Sure, you might see good online results once a while, but you might even not be able to reproduce the success if you were to do it again.
Recently, I face a new problem in ads supply. Think about a typical setting of modern recommendation systems where we need to insert ads in between organic contents. If we insert ads too frequently, user engagement with organic content will drop; if we insert ads too little, the system will have low ads revenue. We will assume in each user session, organic contents and ads are loaded in the unit of “pages”. When the user is close to finishing one page, the next page is formed by having a specific ranking of organic contents and ads. I think an RL policy to decide the best ad insertion positions in each page is promising because as a business, we care about accumulated value (i.e., accumulated engagement or ads revenue). If we look at user trajectories in the unit of pages, there might exist a sequence of ads insertion decisions which can optimize the accumulated value better than any supervised learning-based policy which only optimizes for immediate reward.
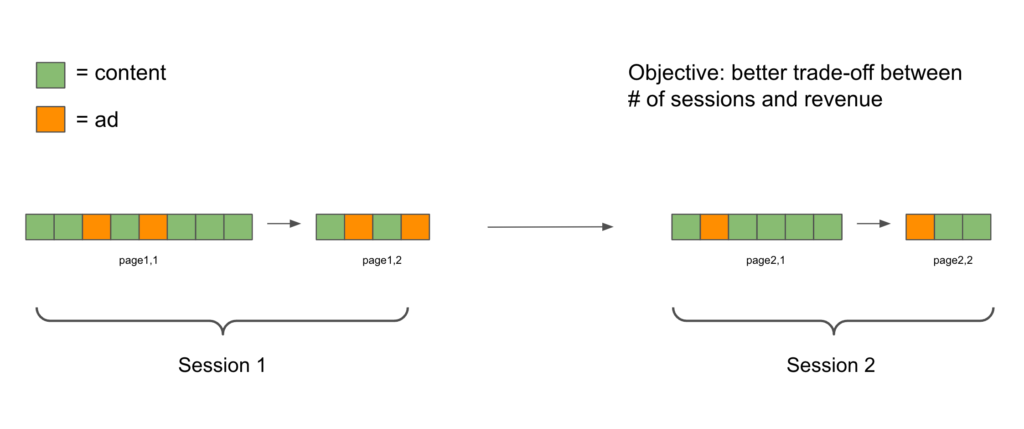
Here is just a hypothetical example why RL can work better than a supervised learning-based policy:
Suppose a user will have a session of 4 pages. Based on a supervised learning model, we will insert 6 ads in each of the first 3 pages; but in the last page, because the user has seen 3 pages of 6-ads and reached fatigue, we have to insert only 1 ads. The supervised learning model will lead to 19 ads inserted in total. However, a reinforcement learning model will know that in order to maximize the accumulated ads inserted, it can place 5 ads in all the 4 pages. The RL model will eventually insert 20 ads, one more than the SL model.
I design an ads supply environment for testing whether an RL policy is working well. In this environment, every user’s behavior is measured within a time window of 7days. They have a default session continuation probability of 0.8 after seeing each page and a default next session returning time of 24 hours. Each page can be inserted 1,2, or 3 ads. Whenever they see two consecutive pages with an average load > 1.5, the page continuation probability will be shrunk by 0.2 factor and next session returning time will also increase 24 hours. The state features include last two pages’ ad loads, the # of sessions and pages so far, etc.
We collect data using the designed simulator and a random data collection policy. The data consists of 1M episodes (equivalent to 10M (S,A,R,S, A) tuples). We compare Q-learning, SARSA, and Monte Carlo Value Regression. Surprisingly, MC performs quite better than the other two and the random data collection policy. Here is the result:
- Random data collection policy: Avg sessions: 2.966372, avg reward: 20.859195
- Q-Learning: Test avg sessions: 4.3327, avg reward: 33.8197
- SARSA: Test avg sessions: 3.808, avg reward: 31.5479
- Monte-Carlo Value Regression: Test avg sessions: 4.6173, avg reward: 43.2075
From this simulation, I become more favorable to always start with simple methods like Monte Carlo Value regression. Advanced RL algorithms may not be the best in a noisy real-world environment.
How to run the code:
- Download the code folder: https://www.dropbox.com/s/p2mfowz9m63zwn7/ads_supply.zip?dl=0
- Run
data_generator.pyto generate training data, which is to be saved tooffline_train_data.pickle - Run
mc_learning.py,q_learning.py, orsarsa.pyto train a model - Run
eval.pyto evaluate model performance. Remember to changeMODEL_SAVE_PATHproperly.