In a previous post, we discussed an earlier generative modeling called Normalizing Flows [1]. However, Normalizing Flows has its own limitations: (1) it requires the flow mapping function  to be invertible. This limits choices of potential neural network architectures to instantiate , because being invertible means that hidden layers must have the exact same dimensionality as the input. (2) computing the log of determinant of the jacobian matrix of is expensive, usually in
to be invertible. This limits choices of potential neural network architectures to instantiate , because being invertible means that hidden layers must have the exact same dimensionality as the input. (2) computing the log of determinant of the jacobian matrix of is expensive, usually in  time complexity.
time complexity.
Flow matching is a more recent developed generative modeling technique with lower training cost (see the comparison between Normalizing Flows vs Flow Matching in [2] and a more mathematical introduction of how Flow Matching evolved from Normalizing Flows [6]). In this post, we are going to introduce it. Two materials help me understand flow matching greatly: (1) neurips flow matching tutorial [3] (2) an MIT teaching material [4]

Flow Matching
Motivation
We start from the motivation. Suppose  represents the target space we want to generate (e.g., all dog pictures with
represents the target space we want to generate (e.g., all dog pictures with  representing the image dimension). The goal of generative modeling is to learn the real target distribution
representing the image dimension). The goal of generative modeling is to learn the real target distribution  . To enable generating different targets stochastically, the goal usually becomes to learn the transformation from an initial random distribution
. To enable generating different targets stochastically, the goal usually becomes to learn the transformation from an initial random distribution  (e.g., Gaussian) the real data distribution .
(e.g., Gaussian) the real data distribution .
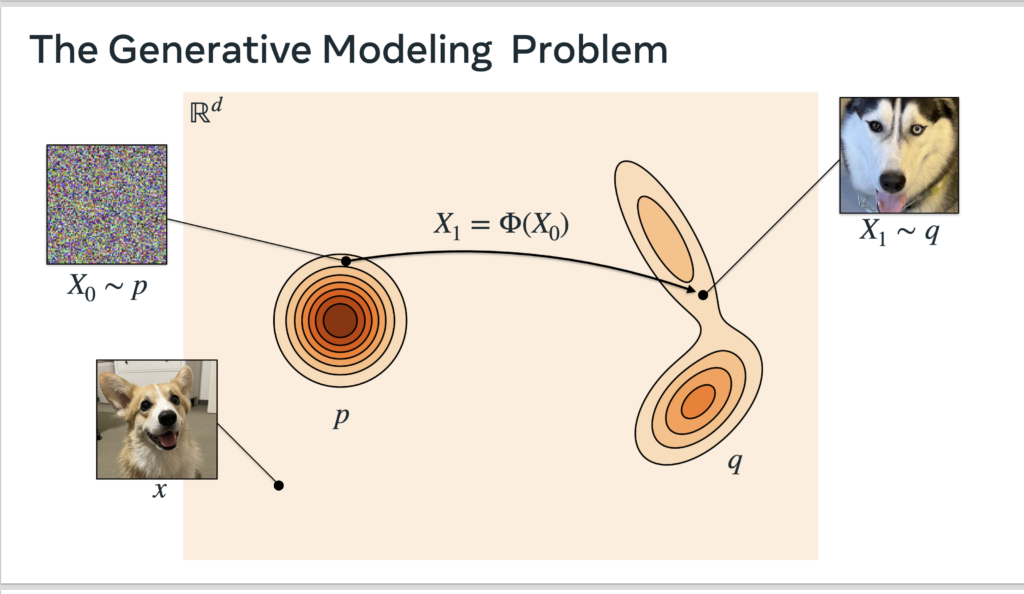
A straightforward method is GAN [5]. However, GAN faces various training instability issues and cannot give the likelihood of a data point, while Flow Matching can address both pain points.
Ordinary Differential Equations (ODE)
ODE describes how a system changes over time. An ODE is defined as:

where ![X: [0, 1] \rightarrow \mathbb{R}^d](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-f9c7da8f7dbe3f55383de3daa935b5c9_l3.png "Rendered by QuickLaTeX.com") . In natural language, we say that
. In natural language, we say that  is a variable representing any point in the -dimensional system at time
is a variable representing any point in the -dimensional system at time  , where each dimension is between 0 and 1. At a given time ( is also between 0 and 1), should move in the direction of
, where each dimension is between 0 and 1. At a given time ( is also between 0 and 1), should move in the direction of  , which we call the velocity. is also a -dimensional vector. The solution of an ODE is called flow,
, which we call the velocity. is also a -dimensional vector. The solution of an ODE is called flow,  , which tells you where an initial point will be at time . Hence ‘s input is an -dimensional point and output is also an -dimensional point. The ODE above can be rewritten with :
, which tells you where an initial point will be at time . Hence ‘s input is an -dimensional point and output is also an -dimensional point. The ODE above can be rewritten with :

The example below shows how a system moves – the red square grid is the flow, describing each initial point’s “landing” point at time , and the blue arrow is the velocity at time .
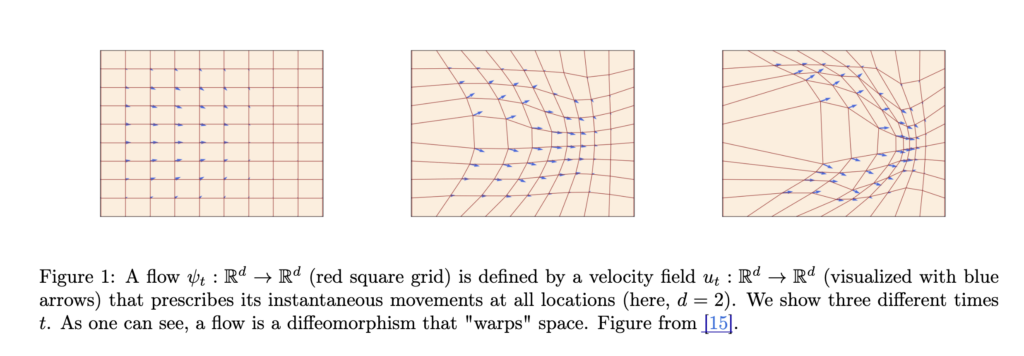 The goal of flow matching is to learn a velocity function
The goal of flow matching is to learn a velocity function  such that
such that  and
and  . With a known/learned velocity function, you can easily simulate how the system changes, which is equivalent to the flow function :
. With a known/learned velocity function, you can easily simulate how the system changes, which is equivalent to the flow function :

Conditional / Marginal Probability Path, Conditional and Marginal Velocity Fields
This section is the most mathematical-heavy one. We first introduce the concept of conditional probability path,  . In natural language, means the distribution of the position of a point at time if that point starts from
. In natural language, means the distribution of the position of a point at time if that point starts from  at time 0 and ends at exactly
at time 0 and ends at exactly  (i.e., a delta distribution at ) at time 1, where is any data sampled from the target distribution
(i.e., a delta distribution at ) at time 1, where is any data sampled from the target distribution  . Therefore, the marginal probability path
. Therefore, the marginal probability path  can be described as:
can be described as:
 .
.
simply describes the position distribution of the whole system at time , given the initial distribution is and the end distribution is .
The diagram below describes an example of conditional probability path : it starts from a 2D gaussian distribution and ends at a particular position marked by the red dot.
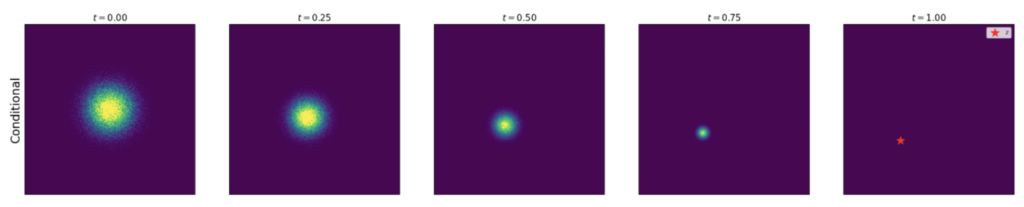
The diagram below describes an example of marginal probability path : it starts from a 2D gaussian distribution and ends at a chessboard-patterned distribution.

Deriving from the concepts of conditional/marginal probability path, we can also have conditional and marginal velocity field, defined as:
Conditional velocity field: 
Marginal velocity field: 
The formula of marginal velocity field needs a bit work to be proved. We use the rest of this section to prove that.
First, we introduce a theorem called Continuity Equation:
 where the divergence operator is defined as:
where the divergence operator is defined as:
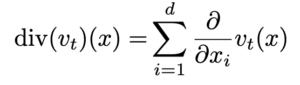
In natural language, this equation says that the change of marginal probability path w.r.t. time is equal to the negative divergence of  . The same theorem can also be applied to the conditional probability path:
. The same theorem can also be applied to the conditional probability path:  .
.
Now we can show that:

By the last two equations, we proved the relationship between the marginal and conditional velocity fields:
Training a Practical Flow Matching model
To reiterate the motivation of flow matching: our goal is to learn a velocity function such that and . Therefore, the ultimate goal should be:
![\mathcal{L}_{FM}(\theta) = \mathbb{E}_{t\sim Unif[0,1], x\sim p_t} \left[ \left\Vert \mu_t^\theta(x)-\mu_t(x) \right\Vert^2 \right] = \mathbb{E}_{t\sim Unif[0,1], z\sim p_{data}, x\sim p_t(\cdot|z)} \left[ \left\Vert \mu_t^\theta(x)-\mu_t(x) \right\Vert^2 \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-8d442e13a50791c6da29960192c9f0db_l3.png "Rendered by QuickLaTeX.com")
Recall in the section above that , which involves an integration operator and thus is intractable. Interestingly, we can prove that ![\mathcal{L}_{FM}(\theta)=\mathbb{E}_{t\sim Unif[0,1], z\sim p_{data}, x\sim p_t(\cdot|z)} \left[ \left\Vert \mu_t^\theta(x)-\mu_t(x) \right\Vert^2 \right] = \mathbb{E}_{t\sim Unif[0,1], z\sim p_{data}, x\sim p_t(\cdot|z)} \left[ \left\Vert \mu_t^\theta(x)-\mu_t(x|z) \right\Vert^2 \right] = \mathcal{L}_{CFM}(\theta)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-1e72627ef5ceb9eb41cd75389f19eec3_l3.png "Rendered by QuickLaTeX.com") . Therefore, we can explicitly regress our parameterized velocity function against a tractable conditional vector field. This proof can be found in Theorem 18 in [4].
. Therefore, we can explicitly regress our parameterized velocity function against a tractable conditional vector field. This proof can be found in Theorem 18 in [4].
The exact form of  depends on what family of probability path we choose. One particularly popular probability path is the Gaussian probability path. We can define
depends on what family of probability path we choose. One particularly popular probability path is the Gaussian probability path. We can define  and
and  to be two continuously differentiable, monotonic functions with
to be two continuously differentiable, monotonic functions with  and
and  . We can verify that the conditional Gaussian probability path parameterized by and ,
. We can verify that the conditional Gaussian probability path parameterized by and ,  , satisfies the definition of a conditional probability path: at time 0,
, satisfies the definition of a conditional probability path: at time 0,  and
and  . Note that, with the Gaussian conditional probability path, we can simulate the position of
. Note that, with the Gaussian conditional probability path, we can simulate the position of  :
:  , where
, where  . We can then prove that
. We can then prove that  (see detailed proof in Example 11 in [4]).
(see detailed proof in Example 11 in [4]).
With all these intermediate artifacts, we can derive the loss function:
![\begin{align*} \mathcal{L}_{CFM}(\theta) &= \mathbb{E}_{t\sim Unif[0,1], z\sim p_{data}, x\sim p_t(\cdot|z)} \left[ \left\Vert \mu_t^\theta(x)-\mu_t(x|z) \right\Vert^2 \right] \\ &= \mathbb{E}_{t\sim Unif[0,1], z\sim p_{data}, x\sim p_t(\cdot|z)} \left[ \left\Vert \mu_t^\theta(x)-\left(\dot{\alpha_t}-\frac{\dot{\beta_t}}{\beta_t}\alpha_t \right)z - \frac{\dot{\beta_t}}{\beta_t}x \right\Vert^2 \right] \\ &(\text{let } x=\alpha_t z + \beta_t \epsilon) \\ &= \mathbb{E}_{t\sim Unif[0,1], z\sim p_{data}, x\sim p_t(\cdot|z)} \left[ \left\Vert \mu_t^\theta(\alpha_t z + \beta_t \epsilon) - (\dot{\alpha_t} z + \dot{\beta_t} \epsilon) \right\Vert^2 \right] &(\text{special case: } alpha_t=t, \beta_t=1-t) \\ &=\mathbb{E}_{t\sim Unif[0,1], z\sim p_{data}, x\sim p_t(\cdot|z)} \left[ \left\Vert \mu_t^\theta(tz+(1-t)\epsilon) - (z- \epsilon) \right\Vert^2 \right] \end{align*}](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-6d2afce51e8290a674829c7bfe31e112_l3.png "Rendered by QuickLaTeX.com")

References
[1] https://czxttkl.com/2021/11/15/normalizing-flows/
[2] https://medium.com/@noraveshfarshad/flow-matching-and-normalizing-flows-49c0b06b2966
[3] https://neurips.cc/virtual/2024/tutorial/99531
[4] https://diffusion.csail.mit.edu/docs/lecture-notes.pdf
[5] https://czxttkl.com/2020/12/24/gan-generative-adversarial-network/
[6] https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html