[This post is inspired by one of my previous posts [4] which combs my thoughts on how to build a validation tool for RL problems. Now, I am trying to comb my thoughts for building tools to facilitate long-term value optimization.]
There is one important topic in applied RL: long-term user value optimization. Usually, this means we want to recommend items that can trigger users’ long-term engagement. However, there are two big hurdles: 1. is the long-term effect measurable/learnable? 2. how do we evaluate an algorithm offline?
Measure long-term effect
My current thought is to train a powerful sequence model which predicts a user immediate engagement from historical sequence consumptions. With this model, we can mask out a single item in the input sequence and observe how much variation of the current item’s engagement occurred due to the mask-out. If there indeed exists long-term effect, the variation of the current item’s engagement prediction should be statistically significant. I wrote a piece of pseudo-code for realizing this idea in ads long-term value optimization:

Google/Youtube recently proposed an interesting data science project for identifying proxy mid-term metrics to optimize for long-term metrics [6]. The motivation is that long-term metrics are usually sparse and noisy so it can be more robust to optimize for mid-term metrics. The paper analyzes a large amount of users’ 20-week video watch sequences. For each user, they divide the 20 weeks into 10 time buckets of 2 weeks. For each time bucket, they compute several diversity and consumption metrics. Therefore, each user will essentially have a sequence of different metrics computed for each 2-weeks time gap. Now, they want to train a classifier for predicting whether low-activeness users will progress to power users at the end of 20 weeks. The input features to the classifier are the metrics in the 2nd time bucket and the difference of metric values between the 1st and 2nd time buckets. They use random forest as the model class, which allows easy feature importance computation after training. Metrics that are commonly found in all different user cohorts are considered good reward functions.
Evaluate an algorithm offline
Now that assume we already have a LTV model which can re-rank items differently from a supervised-learning model, how do we evaluate it such that we know whether the ultimate metric we care about can be improved? Although there exist importance sampling-based approaches, I think the most feasible approach is still model-based because of the complex of real-world problems. Long-term value optimization often happens in the context of slate ranking. We first need to decide how we want to simulate slates once we apply LTV re-ranking. We can have two options:
1. simulate a series of slates a user could watch. My current thought is to utilize some contrastive learning or generative adversarial idea: when we extract a pool of possible items that could be placed into the next simulated slate, certain items are more likely to belong to the slate than others. We can train a model to differentiate items from real slate data and items that are randomly sampled. The model can then be used to simulate (sequences of) slates.
update 09/01/2022:
There is another paper [7] which can inspire how to simulate slates. This paper is from Meta. The architecture is best summarized in the diagram below. They represent each user by their past consumed post sequences. Using Transformers, they can obtain a user embedding at each time step t when the user consumes a post. Note that, when Transformers process the post sequences, they use pre-trained post embeddings. The optimization target is that the user embedding at time t should have high cosine similarity with the post embedding at time t+1 while having low cosine similarity with posts at other time steps. We can adapt this loss function for slate generation such that user embedding at time t should have high cosine similarity with any post in the next logged slate while having low cosine similarity with posts in other slates and from other users.
2. reuse logged slates. Only simulate the re-ranking order within logged slates. This approach implies a big assumption: LTV reranking would not affect how slates are generated. The assumption is not totally unreasonable for offline evaluation purpose. After all, simulating how slates are generated as in option 1 is really a difficult problem.
Once we can simulate slates (or reuse logged slates), we can train another sequence model to simulate how the LTV model helps lift the metric we care about. See the screenshot below for my sketch of idea:
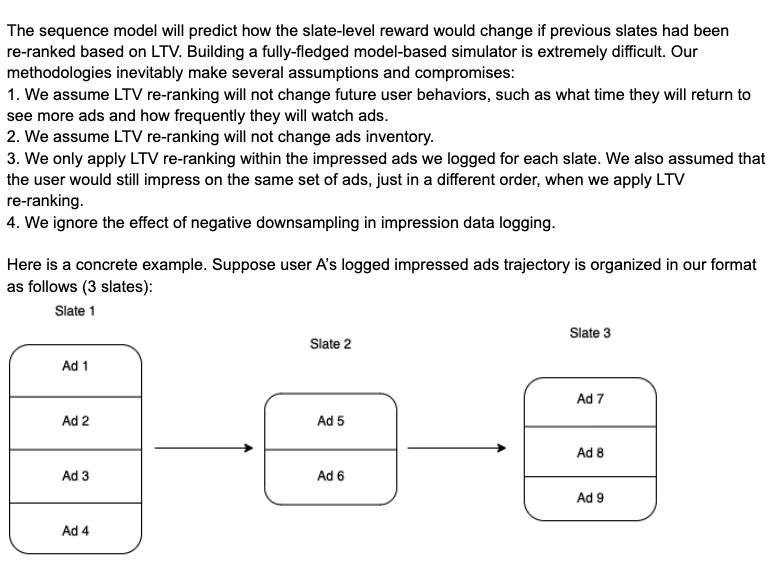
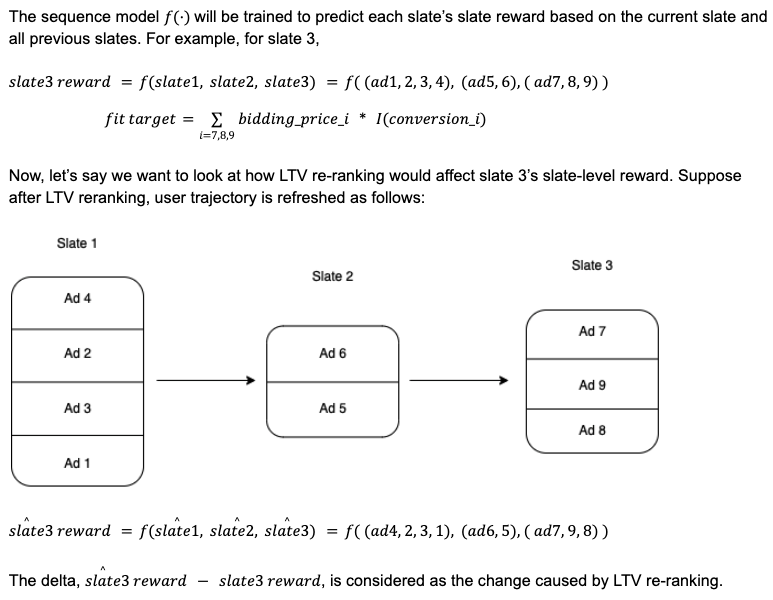
Of course, for both ideas (“measure long-term effect” and “evaluate an algorithm offline”), we can apply uncertainty estimation to make results more reliable. I mentioned how to conduct uncertainty estimation for deep neural networks in [4] and also this post [3] is helpful.
I also stumble upon another paper for counterfactual evaluation [5]. It is applied to a different but related problem: if an ad impression is causal for a later ad conversion. We train a sequential model with an autoregressive decoder. Then, we can simulate user behavior after the ad impression (we call it sequence w1) and before the ad impression (we call it sequence w2). Suppose we simulate a fixed number of steps in w1 and w2 and end at an ad embedding at e1 and e2 respectively. Then, we can compare the distance between d(e1, e_logged) and d(e2, e_logged), where e_logged is the embedding of the ad conversion. If, on average, d(e1, e_logged) < d(e2, e_logged), then that is a signal telling that the ad impression is causal for the conversion.
References
[1] Positive Unlabeled learning with non-negative risk estimator
[2] Pure: positive unlabeled recommendation with generative adversarial network
[3] Deep ensemble: https://machinelearningmastery.com/ensemble-methods-for-deep-learning-neural-networks/
[4] https://czxttkl.com/2020/09/08/tools-needed-to-build-an-rl-debugging-tool/
[5] Shopping in the Multiverse- A Counterfactual Approach to In-Session Attribution: https://arxiv.org/abs/2007.10087
[6] Surrogate for Long-Term User Experience in Recommender Systems: https://dl.acm.org/doi/abs/10.1145/3534678.3539073
[7] NxtPost: User to Post Recommendations in Facebook Groups: https://arxiv.org/pdf/2202.03645.pdf