Diversity of recommendations keeps users engaged and prevents boredom [1]. In this post, I will introduce several machine learning-based methods to achieve diverse recommendations. The literature in this post is mostly retrieved from the overview paper “Recent Advances in Diversified Recommendation” [6].
Determinant Point Process
Let’s first review what is the determinant of a matrix [2]. The determinant of matrix  can be understood as representing the (signed) volume of the parallelepiped transformed from an n-dimensional unit cube by . The parallelepiped is defined by the vertices of coordinates same as ‘s column vectors. Let’s look at a 2D example:
can be understood as representing the (signed) volume of the parallelepiped transformed from an n-dimensional unit cube by . The parallelepiped is defined by the vertices of coordinates same as ‘s column vectors. Let’s look at a 2D example:
(1) 
transforms a unit square on the 2D plane to a parallelogram characterized by two vertices  and
and  (corresponding to ‘s first column and second column). Therefore, according to basic math [3], this parallelogram’s area can be computed as
(corresponding to ‘s first column and second column). Therefore, according to basic math [3], this parallelogram’s area can be computed as  , which is the definition of the determinant of .
, which is the definition of the determinant of .
A point process  on an
on an  -cardinality set
-cardinality set  is a probability distribution over the power set of (i.e.,
is a probability distribution over the power set of (i.e.,  ). Determinant point process represents a family of probability distributions such that for any subset
). Determinant point process represents a family of probability distributions such that for any subset  , its probability density has a closed form as:
, its probability density has a closed form as:
(2) 
where
 is a constructed
is a constructed  matrix indexed by the elements of ,
matrix indexed by the elements of ,  is an identity matrix of the same size, and
is an identity matrix of the same size, and  is a sub-matrix of :
is a sub-matrix of : ![L_s \equiv [L_{ij}]_{i,j \in s}](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-aa26ef8420ba9fff45fdeb156c38c7a1_l3.png "Rendered by QuickLaTeX.com") .
.
can be constructed in a way to give the determinant point process a beautiful interpretation on balancing individual items’ quality and inter-item diversity. First, we can rewrite as a Gram matrix:  , where
, where  has a size
has a size  . Then, each column of can be represented as
. Then, each column of can be represented as  ,
,  , which can be thought of as the normalized feature vector of one item in
, which can be thought of as the normalized feature vector of one item in  (
( ) scaled by a quality scalar
) scaled by a quality scalar  . Next, as we know that
. Next, as we know that  and
and  , we know that
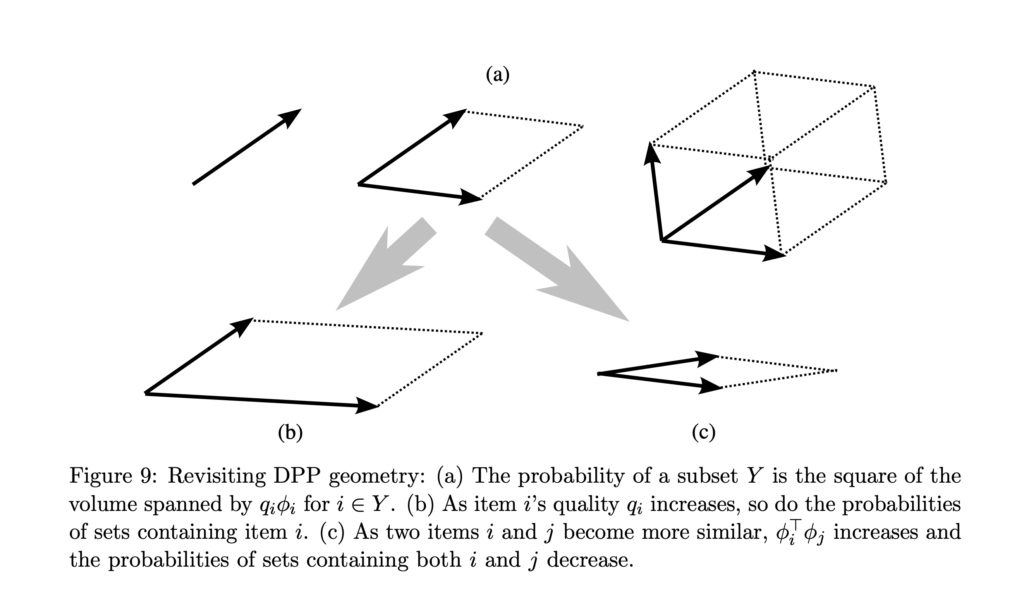
, we know that  . The volume of the parallelepiped characterized by
. The volume of the parallelepiped characterized by  is affected by both and
is affected by both and  . The larger the is, the larger the volume. The larger
. The larger the is, the larger the volume. The larger  (for any
(for any  ) is, the more similar the two items are, and consequently the smaller the volume is. This can be best understood in when
) is, the more similar the two items are, and consequently the smaller the volume is. This can be best understood in when  or
or  :
:
We denote  as the best subset of that can achieves the highest
as the best subset of that can achieves the highest  . Now we introduce a concept: is log-submodular (Section 2.2 in [7]). Suppose
. Now we introduce a concept: is log-submodular (Section 2.2 in [7]). Suppose  . Then
. Then  is submodular because
is submodular because  for any
for any  . Intuitively, adding elements to yields diminishing returns in as is getting large. As [5] reveals (around Eqn. 74), is also non-monotone, as the additional of even a single element can decrease the probability. Submodular maximization corresponds to finding that has the highest (or
. Intuitively, adding elements to yields diminishing returns in as is getting large. As [5] reveals (around Eqn. 74), is also non-monotone, as the additional of even a single element can decrease the probability. Submodular maximization corresponds to finding that has the highest (or  ). Submodular maximization is NP-hard (i.e., can be reduced to an NP problem in polynomial time). (But interestingly, submodular minimization can be solved exactly in polynomial time, see introduction in Section 1.2.1 in one’s thesis). Therefore, in practice, we turn to approximate method for maximization. [4] introduces one simple greedy algorithm (Eqn. 15).
). Submodular maximization is NP-hard (i.e., can be reduced to an NP problem in polynomial time). (But interestingly, submodular minimization can be solved exactly in polynomial time, see introduction in Section 1.2.1 in one’s thesis). Therefore, in practice, we turn to approximate method for maximization. [4] introduces one simple greedy algorithm (Eqn. 15).
Simple Submodular Diversification
Before DPP is introduced to solve the diversification problem, Amazon has proposed a simpler idea to model diversification [9], which is also one kind of submodular minimization.

Here,  is an item candidate set,
is an item candidate set,  is each item’s category (one-hot vector),
is each item’s category (one-hot vector),  is the score of each item, and
is the score of each item, and  is a utility vector for governing the total utility of the final selected item set. The optimal item set will optimize
is a utility vector for governing the total utility of the final selected item set. The optimal item set will optimize  . And in practice it is optimized by a greedy method. is the only learnable parameter of the same dimension as the number of categories. If we want to learn a global optimal , we will need to estimate each category’s CTR by bayesian probability. If we want to learn a personalized , we will need to estimate each user’s CTR on each category.
. And in practice it is optimized by a greedy method. is the only learnable parameter of the same dimension as the number of categories. If we want to learn a global optimal , we will need to estimate each category’s CTR by bayesian probability. If we want to learn a personalized , we will need to estimate each user’s CTR on each category.
Calibrate recommendation to user history
[8] introduces another idea of doing calibration. The tenet of it is that the recommended list should have similar topic distributions as the user watched history. You can look at Section 3 of [8] to get the exact formula. Basically, they use KL-divergence to measure the difference between the recommendation and user history.
References
[1] https://about.instagram.com/blog/engineering/on-the-value-of-diversified-recommendations
[2] https://en.wikipedia.org/wiki/Determinant#Geometric_meaning
[3] https://socratic.org/questions/how-do-you-find-the-area-of-a-parallelogram-with-vertices
[4] Practical Diversified Recommendations on YouTube with Determinantal Point Processes
[5] Determinantal point processes for machine learning
[6] Recent Advances in Diversified Recommendation
[7] Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity