I’ve given a causal inference 101 in [7]. Since then I have been learning more and more about causal inference. I find Jonas Peters’ series of lectures quite good [1~4]. In this post, I am going to take some notes as I watch his lectures, and I am going to share some classic papers in causal inference.
11:27 in [2], Jonas talked about two-stage regression. The problem is as follows. You want to know the causal effect of  on
on  but there is some unobserved confounding factor that may impede your estimation (i.e., you can’t directly do
but there is some unobserved confounding factor that may impede your estimation (i.e., you can’t directly do  regression). So we can introduce an instrument variable
regression). So we can introduce an instrument variable  which does not directly cause by assumption. In the example he gave, is smoking, is lung cancer, and
which does not directly cause by assumption. In the example he gave, is smoking, is lung cancer, and  is some hidden confounding factor that may affect and , for example, stress level. is the tax on tobacco. By intuition, we assume the tax on tobacco doesn’t cause the change in stress level and lung cancer.
is some hidden confounding factor that may affect and , for example, stress level. is the tax on tobacco. By intuition, we assume the tax on tobacco doesn’t cause the change in stress level and lung cancer.
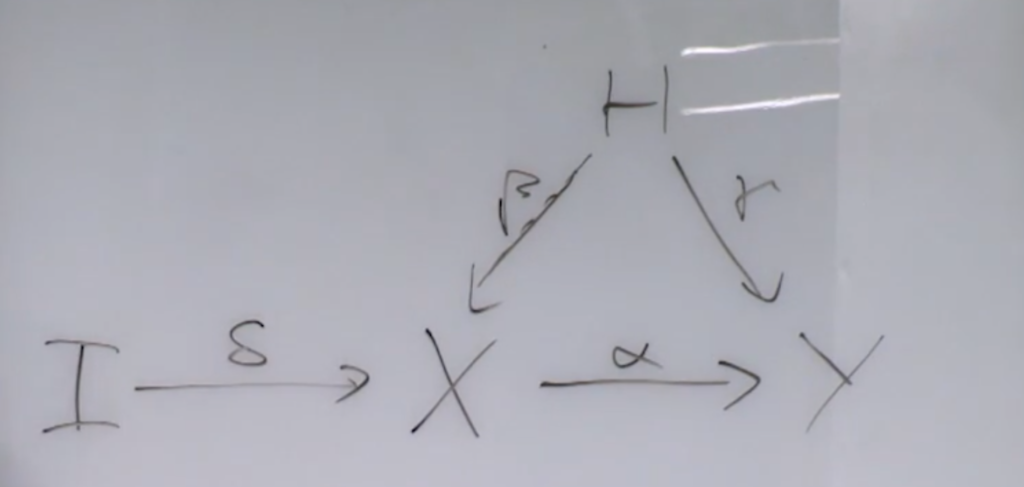
It must be a linear system for two-stage regression to work. We assume the underlying system can be described by the following linear equations:


Therefore, by replacing ‘s equation into , we have:
From the above equation, it becomes clear how to estimate  without depending on . First, we regress on , so that we can obtain
without depending on . First, we regress on , so that we can obtain  . Then using the fitted value of :
. Then using the fitted value of :  , we regress on
, we regress on  . The coefficient learned that is associated with would be roughly , because the rest components
. The coefficient learned that is associated with would be roughly , because the rest components  in is independent of
in is independent of  .
.
However, this method would not work if the system is non-linear because then it is hard to separate from the rest components. would be intertwined in different components which can’t be learned easily.
A real-world application of using two-stage regression is [5], where is time spent on different video types, is overall user satisfaction, is some hidden user preference that may cause both users spending time on videos and their satisfaction. To really understand the magnitude of causal effect of video watch time and user satisfaction, they look at data from different online A/B test groups, with being a one-hot encoding of the test group a data belong to. Following the same procedure as two-stage regression, we can argue that does not cause either or directly. The contribution of [5] is it reduces the bias when estimating the causal effect .
28:00 in [2], Jonas introduced counterfactual distribution. He introduced an example which I think can best illustrate the difference between intervention distribution and counterfactual distribution. See their notations from “Notation and Terminology” in [6]. 
The example goes by follows.
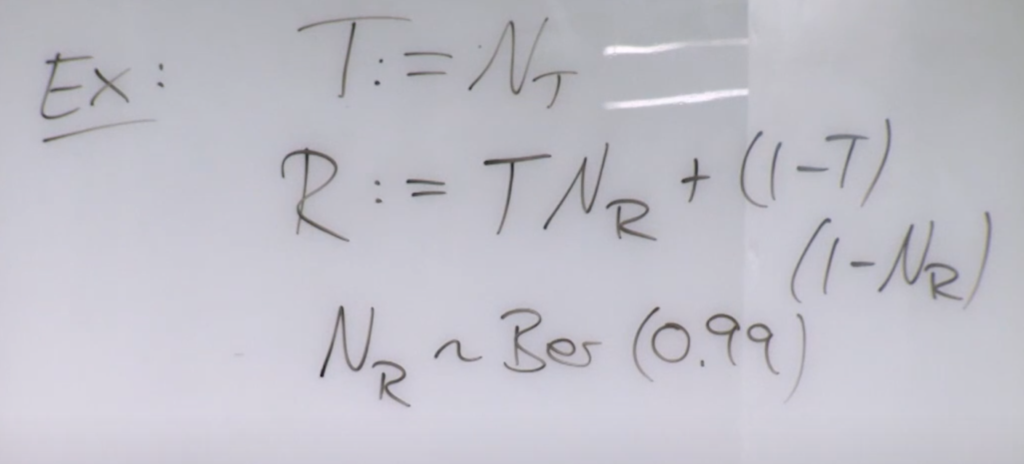
Suppose  is a treatment to a disease.
is a treatment to a disease.  is the recovery result, which depends on whether one receives the treatment and a noise
is the recovery result, which depends on whether one receives the treatment and a noise  following a Bernoulli distribution. According to the provided structural causal model (SCM), the intervention distribution of
following a Bernoulli distribution. According to the provided structural causal model (SCM), the intervention distribution of  would be . In natural language, a patient will have 0.99 probability to recover if received the treatment.
would be . In natural language, a patient will have 0.99 probability to recover if received the treatment.
However, if we observed a specific patient who receives the treatment but did not recover, then we know this patient’s is sampled at value 0. So his counterfactual distribution if he were not received the treatment is  . Note that this specific patient has a new SCM:
. Note that this specific patient has a new SCM:  ,
,  . The counterfactual distribution
. The counterfactual distribution  on the old SCM would be the same as the intervention distribution on the new SCM.
on the old SCM would be the same as the intervention distribution on the new SCM.
I’ve talked about causal discovery using regression and noise independence test in [7]. Here is one another more example. In a CV paper [8], the authors want to determine the arrow of time given video frames. They model the time series’ next value as a linear function of the past two values plus additive independent noise. The final result shows that the forward-time series has a higher independence test p-value than the backward-time series. (A high p-value means we cannot reject the null hypothesis that the noise is independent of the input.) They only keep the data as valid time-series if the noise in the regression model for one direction at least is non-Gaussian, determined by a normality test. The noise independence test is “based on an estimate of the Hilbert-Schmidt norm of the cross-covariance operator between two reproducing kernel Hilbert spaces associated with the two variables whose in- dependence we are testing”.
Another interesting idea about causal discovery is causal invariant prediction. The goal of causal invariant prediction is to find all parents that cause a variable of interest among all possible features  . The core assumption of causal invariant prediction is that in a SCM and any inventional distribution based on it,
. The core assumption of causal invariant prediction is that in a SCM and any inventional distribution based on it,  remains invariant if the structural equation for does not change. Therefore based on data from different SCMs of the same set of variables (which can be observational data or interventional experiments), we can try to fit a linear regression
remains invariant if the structural equation for does not change. Therefore based on data from different SCMs of the same set of variables (which can be observational data or interventional experiments), we can try to fit a linear regression  for every feature subset
for every feature subset  for each SCM. Across different SCMs, we would find all
for each SCM. Across different SCMs, we would find all  ‘s which lead to the same estimation of
‘s which lead to the same estimation of  . Then the parent of is the intersection of all the filtered ‘s because the interaction features’s relationship to remains invariant all the time, satisfying our assumption of causal invariant prediction. [9] applies causal invariant prediction on gene perturbation experiments and I find the example in Table 1 is very illustrative.
. Then the parent of is the intersection of all the filtered ‘s because the interaction features’s relationship to remains invariant all the time, satisfying our assumption of causal invariant prediction. [9] applies causal invariant prediction on gene perturbation experiments and I find the example in Table 1 is very illustrative.

References
[1] Lecture 1: https://www.youtube.com/watch?v=zvrcyqcN9Wo&t=2642s
[2] Lecture 2: https://www.youtube.com/watch?v=bHOGP5o3Vu0
[3] Lecture 3: https://www.youtube.com/watch?v=Jp4UcgpVA2I&t=4051s
[4] Lecture 4: https://www.youtube.com/watch?v=ytnr_2dyyMU
[5] Learning causal effects from many randomized experiments using regularized instrumental variables:
https://arxiv.org/abs/1701.01140
[6] Elements of Causal Inference: https://library.oapen.org/bitstream/handle/20.500.12657/26040/11283.pdf?sequence=1&isAllowed=y
[7] https://czxttkl.com/2020/09/08/tools-needed-to-build-an-rl-debugging-tool/
[8] Seeing the Arrow of Time: https://www.robots.ox.ac.uk/~vgg/publications/2014/Pickup14/pickup14.pdf
[9] Methods for causal inference from gene perturbation experiments and validation: https://www.pnas.org/content/113/27/7361