DistributedDataParallel implements data parallelism at the module level which can run across different machines. There is one process running on each device where one copy of the module is held. Each process loads its own data which is non-overlapping with other processes’. At the initialization phase, all copies are synchronized to ensure they start from the same initialized weights. The forward pass is executed independently on each device, during which no communication is needed. In the backward pass, the gradients are all-reduced across the devices, ensuring that each device ends up with identical copy of the gradients/weights, therefore eliminating the need for model syncs at the beginning of each iteration [1].
[2] illustrates some more detailed design. For example, parameters can be synchronized more efficiently by bucketing. Parameters will be bucketed into several buckets. In the backward phase, whenever the gradient is ready for all the members in a bucket, the synchronization will kick off for that bucket. Thus one does not need to wait for the gradients of ALL parameters to become ready before synchronization starts.
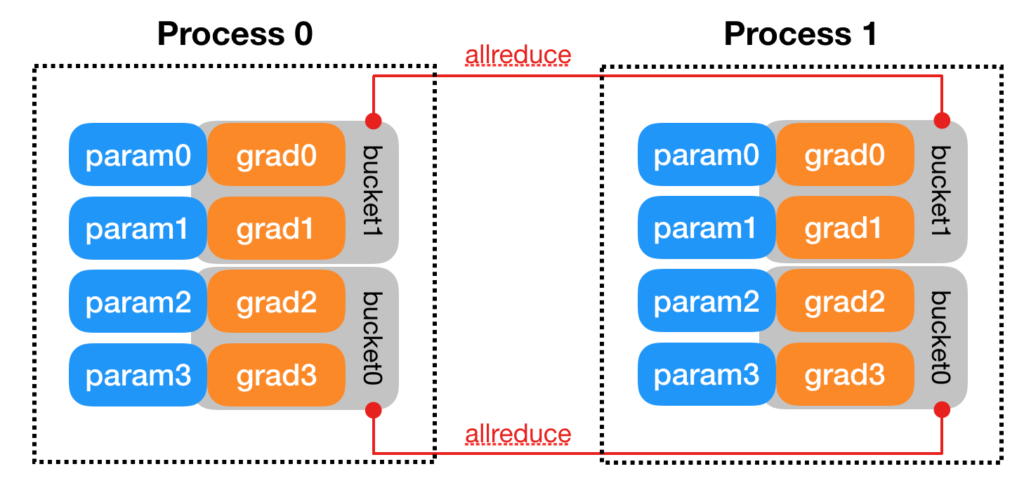
Another detail in [2] is how gradient synchronization is started in the backward phase. It says that “DDP uses autograd hooks registered at construction time to trigger gradients synchronizations. “
I did a quick experiment to verify these design details. test_multi_gpu is in charge of spawning worker processes and the real model training happens in the _worker function. initialize_trainer is the piece of code for initializing models at each process. Check out my comment in “Logs” section in the pseudocode below for the explanation for DPP’s behavior.
def test_multi_gpu(
use_gpu: bool,
num_gpus: int,
normalization_data_map: Dict[str, NormalizationData],
reader_options: ReaderOptions,
):
logger.info(f"Enter test_multi_gpu with reader options {reader_options}")
# These ENVS are needed by torch.distributed: https://fburl.com/1i86h2yg
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = str(find_unused_port())
manager = mp.Manager()
result_dict = manager.dict()
workflow_run_id = flow.get_flow_environ().workflow_run_id
# The second condition is to avoid collision in unit test.
# When running unit test, a local DB is used.
# As a result, the workflow run ID may not be unique.
if workflow_run_id and workflow_run_id > 10000:
init_method = f"zeus://{workflow_run_id}"
else:
host_name = socket.gethostname()
process_id = os.getpid()
init_method = f"zeus://{host_name}_{process_id}"
backend = "nccl" if use_gpu else "gloo"
mp.spawn(
_worker,
args=(
use_gpu,
num_gpus,
backend,
init_method,
reader_options,
normalization_data_map,
result_dict,
),
nprocs=num_gpus,
join=True,
)
logger.info("finish spawn")
def _worker(
rank: int,
use_gpu: bool,
world_size: int,
backend: str,
init_method: str,
reader_options: ReaderOptions,
normalization_data_map: Dict[str, NormalizationData],
reward_options: Optional[RewardOptions] = None,
warmstart_path: Optional[str] = None,
output_dict=None,
):
logger.info(f"rank={rank} with reader options {reader_options}")
dist.init_process_group(
backend=backend, init_method=init_method, world_size=world_size, rank=rank
)
if use_gpu:
torch.cuda.set_device(rank)
model = create_model(...)
trainer = model.initialize_trainer(
use_gpu=use_gpu,
reward_options=reward_options,
normalization_data_map=normalization_data_map,
warmstart_path=warmstart_path,
)
logger.info(f"rank={rank} finish initialize")
num_of_data = 0
data_reader = construct_distributed_data_reader(
normalization_data_map, reader_options
)
for idx, batch in enumerate(data_reader):
batch = post_data_loader_preprocessor(batch)
if use_gpu:
batch = batch.cuda()
num_of_data += len(batch.training_input.state.float_features)
logger.info(
f"rank={rank} batch state={batch.training_input.state.float_features}"
)
logger.info(
f"rank={rank} before train seq2slate param={print_param(trainer.seq2slate_net.seq2slate_net.seq2slate)}"
)
if rank == 1:
logger.info(f"rank={rank} wake")
time.sleep(60)
logger.info(f"rank={rank} sleep")
trainer.train(batch)
logger.info(
f"rank={rank} after train seq2slate param={print_param(trainer.seq2slate_net.seq2slate_net.seq2slate)}"
)
break
logger.info(f"rank={rank} finish reading {num_of_data} data")
def initialize_trainer(self) -> Seq2SlateTrainer:
seq2slate_net = initialize_model(...)
if self.use_gpu:
seq2slate_net = seq2slate_net.cuda()
logger.info(f"Within manager {print_param(seq2slate_net.seq2slate)}")
logger.info(
f"Within manager {next(seq2slate_net.seq2slate.parameters()).device}"
)
if self.trainer_param.num_parallel > 1:
seq2slate_net = _DistributedSeq2SlateNet(seq2slate_net)
return _initialize_trainer(seq2slate_net)
###############
Logs
###############
# This is printed within manager.initialize_trainer to show that
# models are initially with different parameters
# (see line 66 then line 112~115):
I1003 063214.340 seq2slate_transformer.py:140] Within manager tensor([-0.2585, 0.3716, -0.1077, -0.2114, 0.1636, 0.1398, -0.2960, -0.1204,\n ...], device='cuda:0', grad_fn=<CatBackward>)
I1003 063214.341 seq2slate_transformer.py:142] Within manager cuda:0
I1003 063214.349 seq2slate_transformer.py:140] Within manager tensor([-0.1076, -0.0444, 0.3003, -0.1177, 0.0275, -0.0811, 0.2084, 0.3369,\n ...], device='cuda:1', grad_fn=<CatBackward>)
# Below is printed from line 85 ~ 90
# You can see that each process receives different, non-overlapping data
# You can also see that at this point, the two models have the same parameters,
# which are ensured by DDP. The parameters come from one particular copy (rank=0)
I1003 063214.531 test_multi_gpu.py:144] rank=0 batch state=tensor([[ 0.0000, 0.0000, -0.0000, ..., -1.6131, -1.6298, -1.6118],\n ...]],\n device='cuda:0')
I1003 063214.540 test_multi_gpu.py:147] rank=0 before train seq2slate param=tensor([-0.2585, 0.3716, -0.1077, -0.2114, 0.1636, 0.1398, -0.2960, -0.1204,\n
...], device='cuda:0', grad_fn=<CatBackward>)
I1003 063214.544 test_multi_gpu.py:144] rank=1 batch state=tensor([[ 0.0000, 0.0000, -0.7115, ..., -2.2678, -2.3524, -2.4194],\n ...]],\n device='cuda:1')
I1003 063214.553 test_multi_gpu.py:147] rank=1 before train seq2slate param=tensor([-0.2585, 0.3716, -0.1077, -0.2114, 0.1636, 0.1398, -0.2960, -0.1204,\n ..., device='cuda:1', grad_fn=<CatBackward>)
# We deliberately let rank 1 sleep for one minute.
# But you can see that rank 0 does not return from its train function earlier
# because it blocks on .backward function, waiting for rank 1's backward() finish.
# You can see after .train function, both processes have resulted to the same parameters again
I1003 063214.554 test_multi_gpu.py:150] rank=1 wake
I1003 063314.613 test_multi_gpu.py:152] rank=1 sleep
I1003 063315.023 seq2slate_trainer.py:181] 1 batch: ips_loss=-2.706389904022217, clamped_ips_loss=-2.706389904022217, baseline_loss=0.0, max_ips=27.303083419799805, mean_ips=0.6373803615570068, grad_update=True
I1003 063315.033 test_multi_gpu.py:156] rank=0 after train seq2slate param=tensor([-0.2485, 0.3616, -0.0977, -0.2214, 0.1736, 0.1298, -0.3060, -0.1304,\n ...], device='cuda:0', grad_fn=<CatBackward>)
I1003 063315.033 test_multi_gpu.py:161] rank=0 finish reading 1024 data
I1003 063315.039 seq2slate_trainer.py:181] 1 batch: ips_loss=-2.7534916400909424, clamped_ips_loss=-2.7534916400909424, baseline_loss=0.0, max_ips=272.4482116699219, mean_ips=0.908729612827301, grad_update=True
I1003 063315.050 test_multi_gpu.py:156] rank=1 after train seq2slate param=tensor([-0.2485, 0.3616, -0.0977, -0.2214, 0.1736, 0.1298, -0.3060, -0.1304,\n ...], device='cuda:1', grad_fn=<CatBackward>)
I1003 063315.050 test_multi_gpu.py:161] rank=1 finish reading 1024 data
References
[1] https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/