This post curates some distributed RL research.
We start from A3C [2], which we briefly covered a few years ago [3]. The core idea is that there is a central global network which is periodically synchronized with workers. Each worker copies the network parameters from the global network, runs through the environment and collects experiences, and computes gradients on its own machine. Then, it sends the gradients to the global network, where the parameters actually get updated, and then gets back the updated global network parameters [4]. Each worker updates the global network at different “asynchronous” time points, therefore the “asynchronous” in A3C.

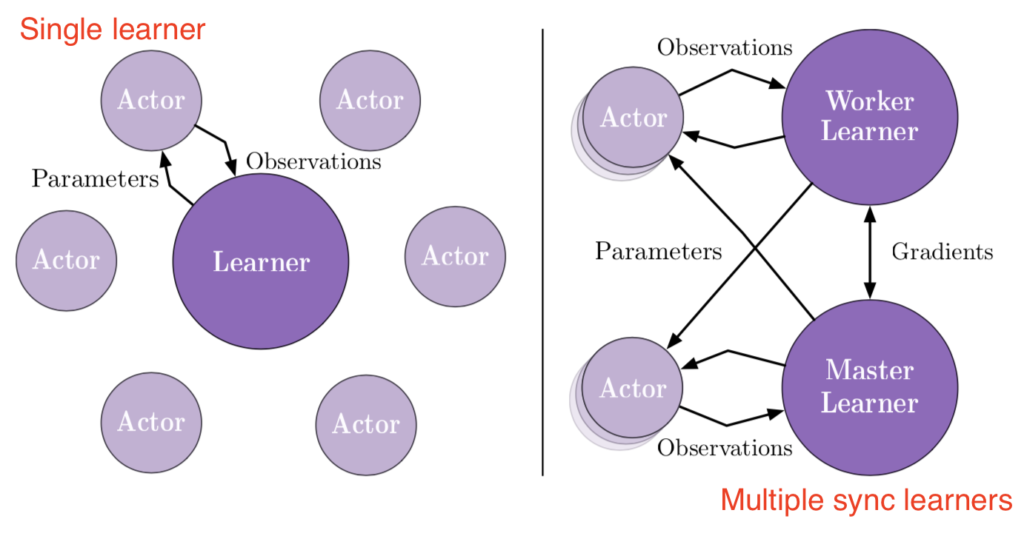
The problem of A3C is that workers may run with lagged parameters. Therefore the computed gradients from different workers may contradict with each other or with the global version. Therefore sometimes it is better to wait for all workers finish before one global update happens [5]:
 This means at any time of A2C all workers and the global network always have the same parameters. Of course, the drawback of A2C is that the speed of one global gradient update is determined by the slowest worker.
This means at any time of A2C all workers and the global network always have the same parameters. Of course, the drawback of A2C is that the speed of one global gradient update is determined by the slowest worker.
IMPALA [1] overcomes some drawbacks of A2C/A3C. IMPALA is conceptually closer to A3C in that there are also workers running on different versions of parameters to collect experience. The global controller can update the global network parameters whenever it receives message from one worker independently of other workers’ progress. Therefore, IMPALA (and A3C) is expected to have higher experience collection throughput than A2C. IMPALA solves the issue of worker policies lagging behind the global version with two methods: (1) workers send trajectories, rather than computed gradient as in A3C, to the global controller. The sent trajectories contain action propensities by the worker network; (2) once the global controller receives trajectories from one worker, it can use V-trace in gradient computation, something similar to importance sampling weighting to adjust discrepancy between the worker policy and the global policy.
Seed RL [7] is another attempt to improve over IMPALA with two motivated observations:
(1) in IMPALA there are two things sent over the network: trajectories (from workers to the global controller) and model parameters (from the global controller to workers). However model parameters can be a number of times larger than trajectories, meaning network bandwidth is wasted a lot on sending parameters of large models.
(2) workers are usually CPU-based, which are slow to perform policies (inference).
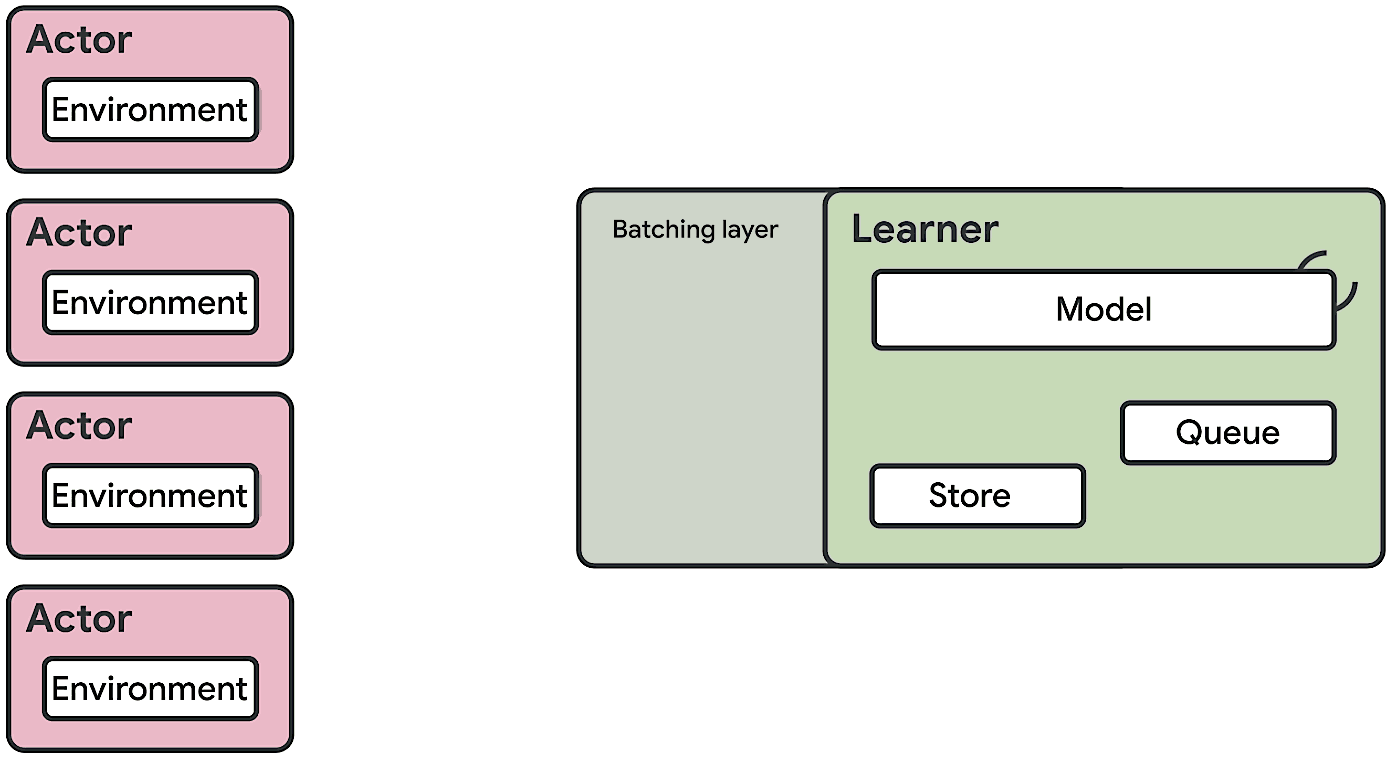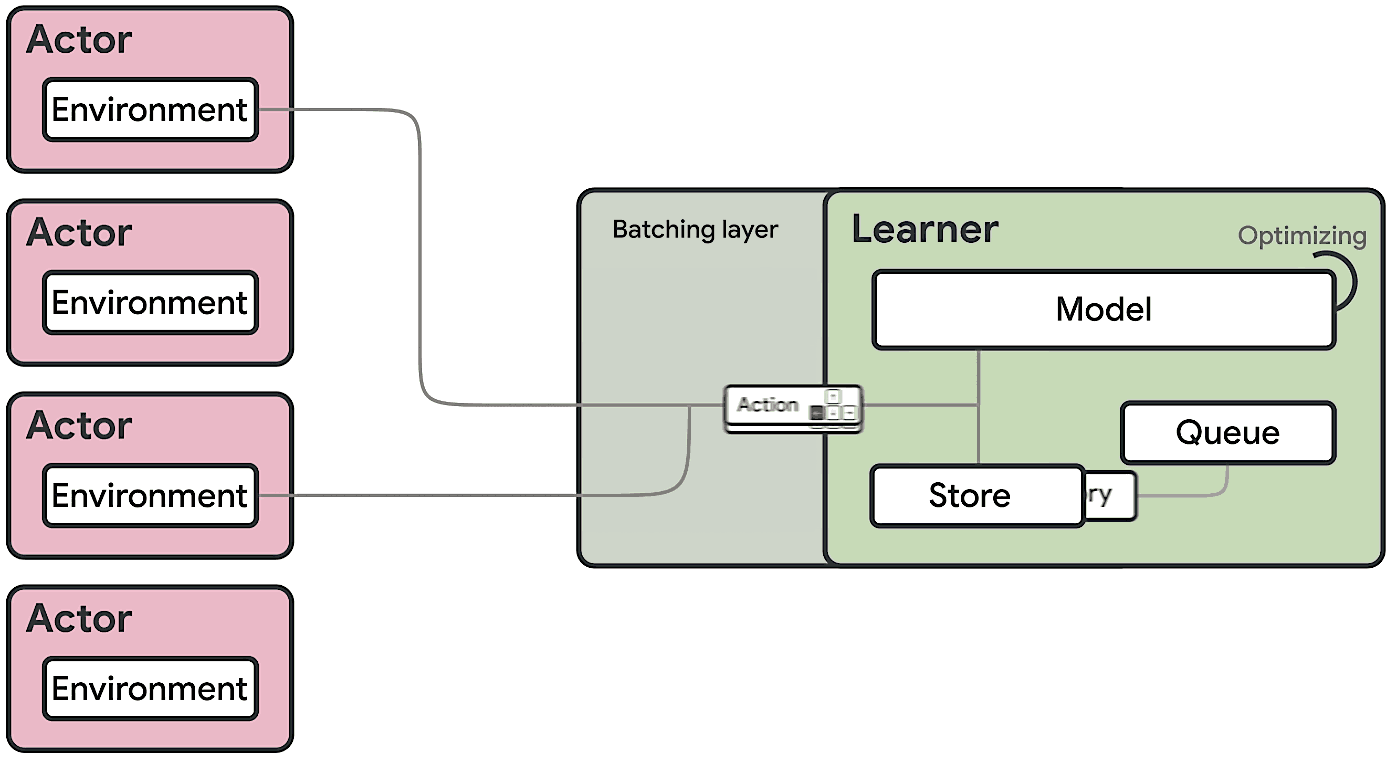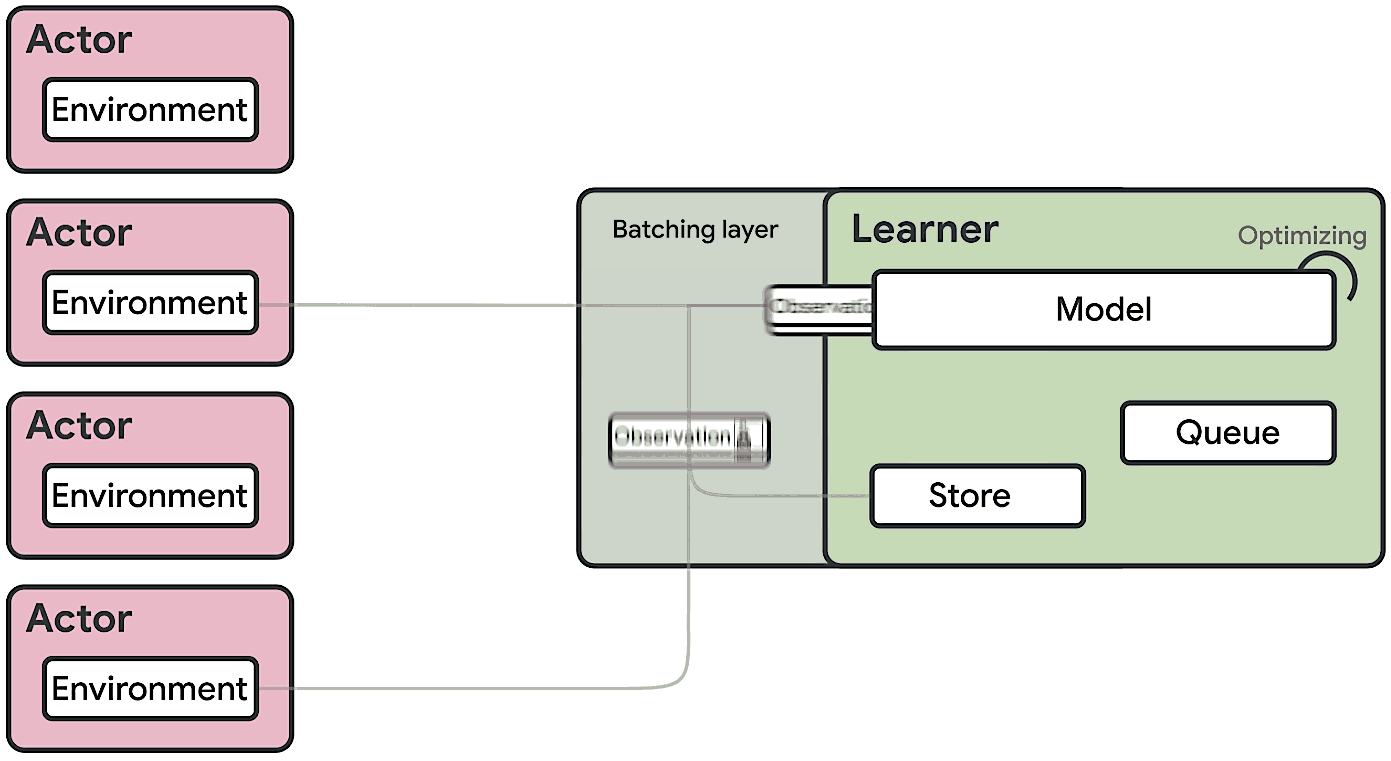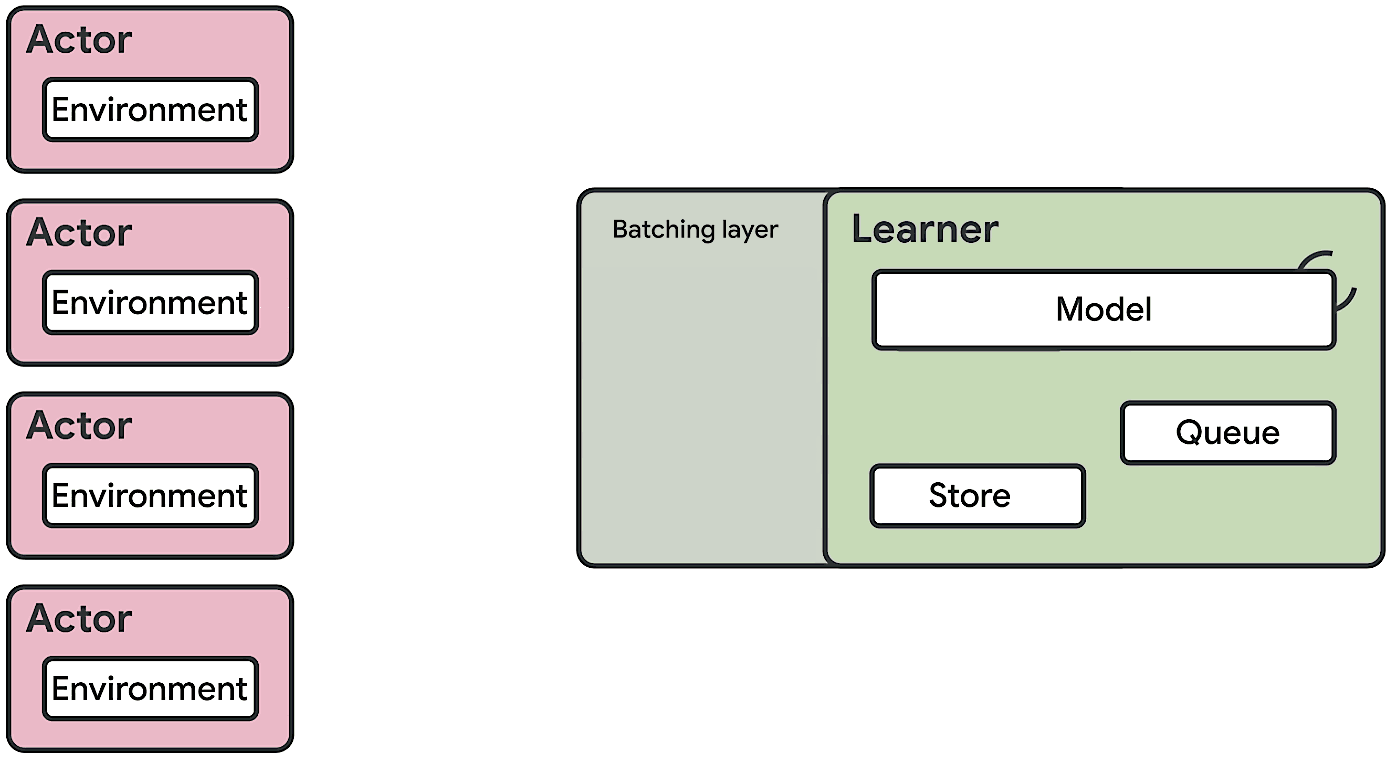
Seed RL doesn’t send model parameters over the network. It performs learning and inference on the global controller, which is usually equipped with GPU. The global controller only sends inferred action outputs to workers and workers send trajectories to the global controller (this is the same as IMPALA). Seed RL also uses V-Trace as it is still an asynchronous algorithm in which workers can fall behind than the global.
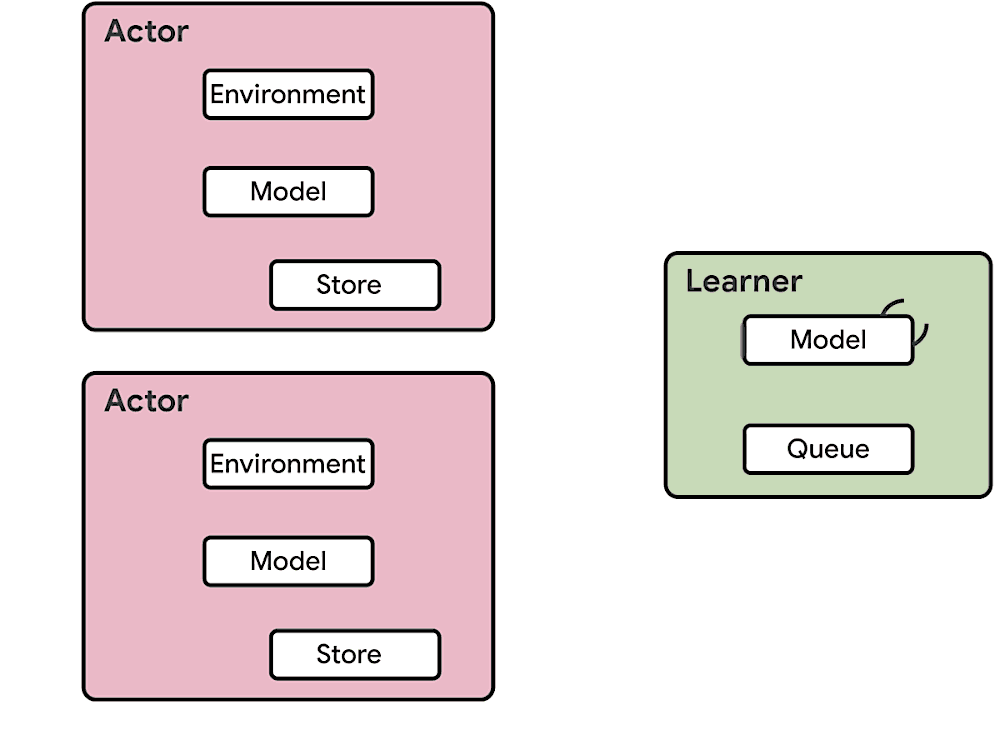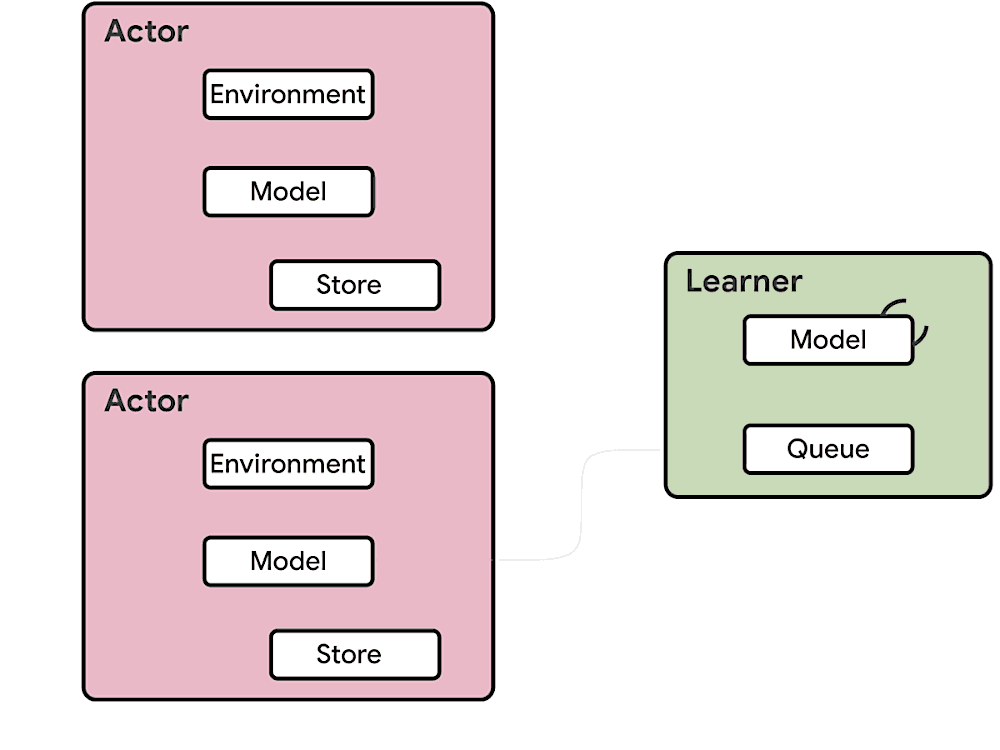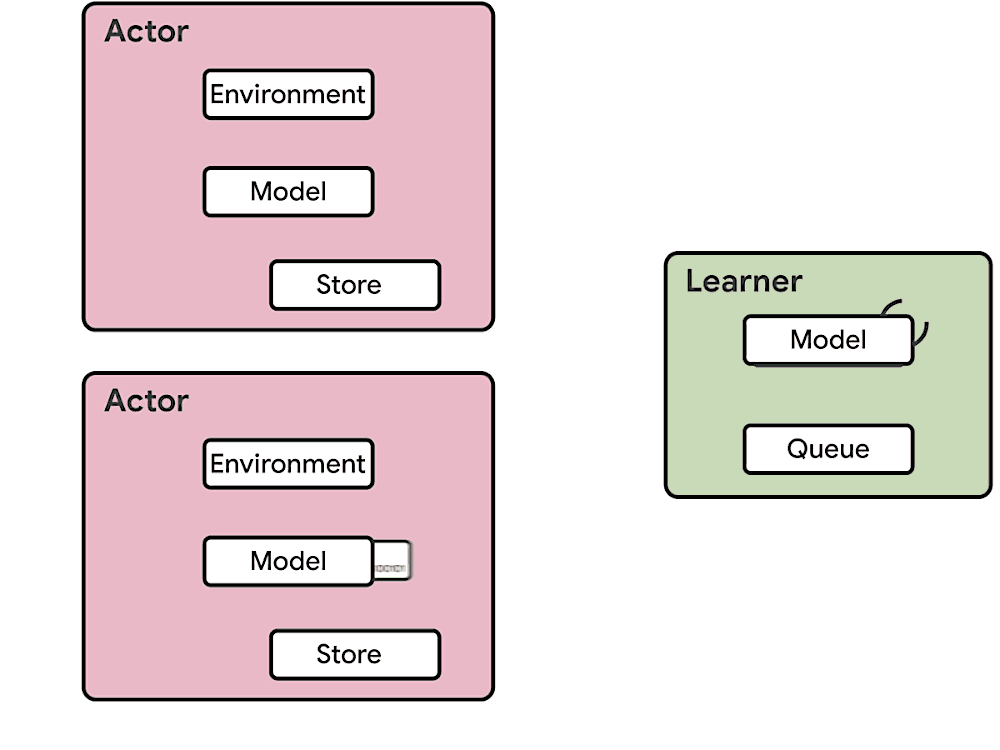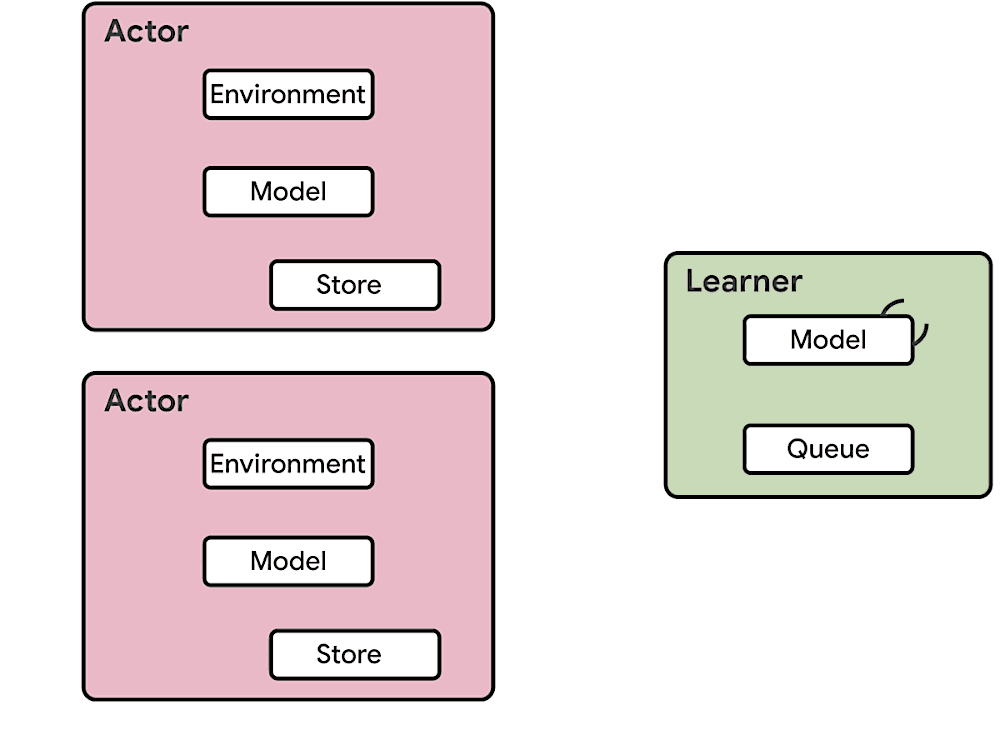
The difference between Seed RL and IMPALA can be best viewed in the following diagrams [6]:
References
[1] IMPALA
[2] A2C / A3C
[3] https://czxttkl.com/2017/06/13/a3c-code-walkthrough/
[5] https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html#a2c
[6] https://ai.googleblog.com/2020/03/massively-scaling-reinforcement.html