Share some thoughts on this paper: Recommending What Video to Watch Next: A Multitask Ranking System [1]
The main contribution of this work is two parts: (1) a network architecture that learns on multiple objectives; (2) handles position bias in the same model
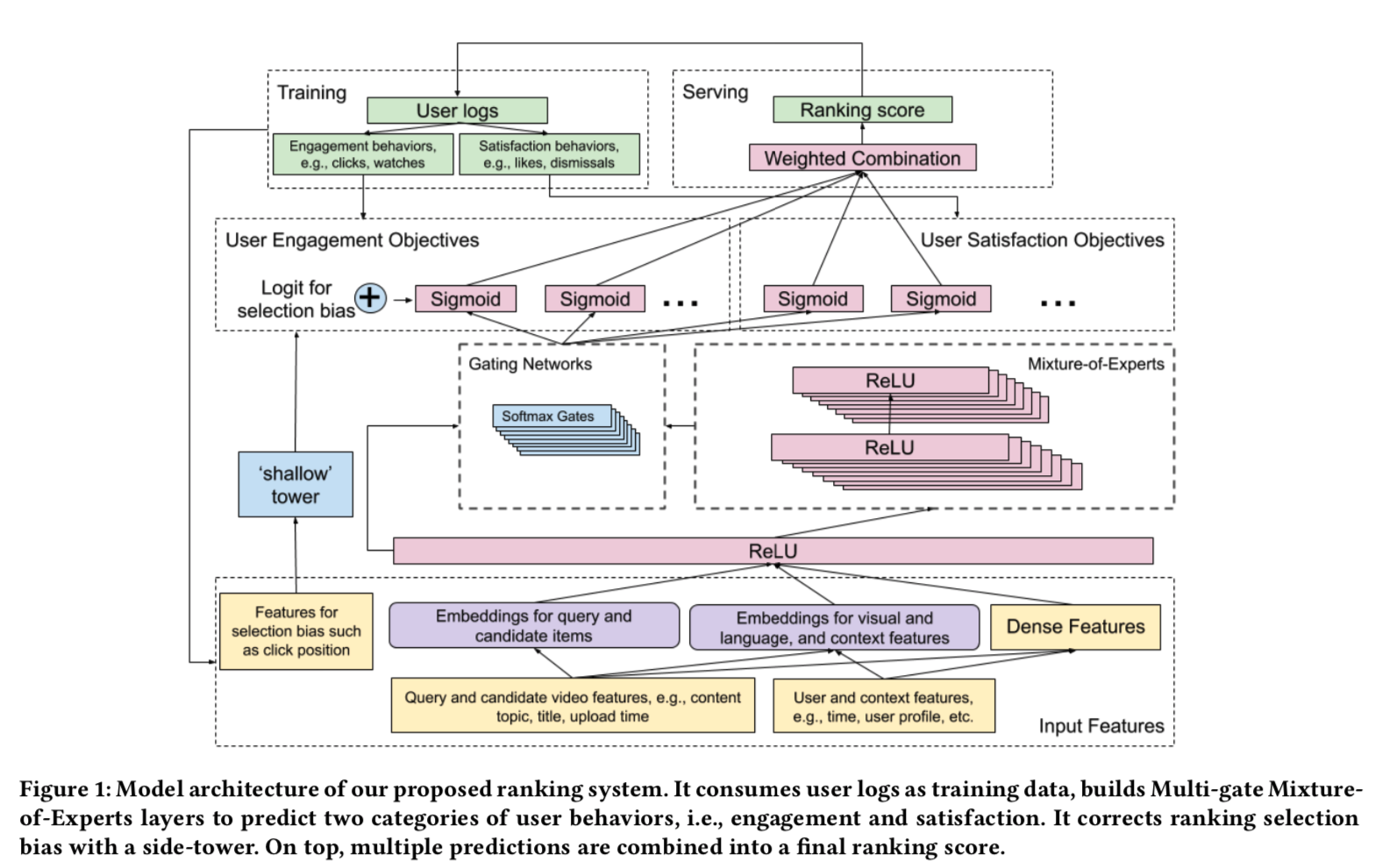
To first contribution is achieved by “soft” shared layers. So each objective does not necessarily use one set of expert parameters; instead it can use multiple sets of expert parameters controlled by a gating network:


The second contribution is to have a shallow network directly accounting for positions.
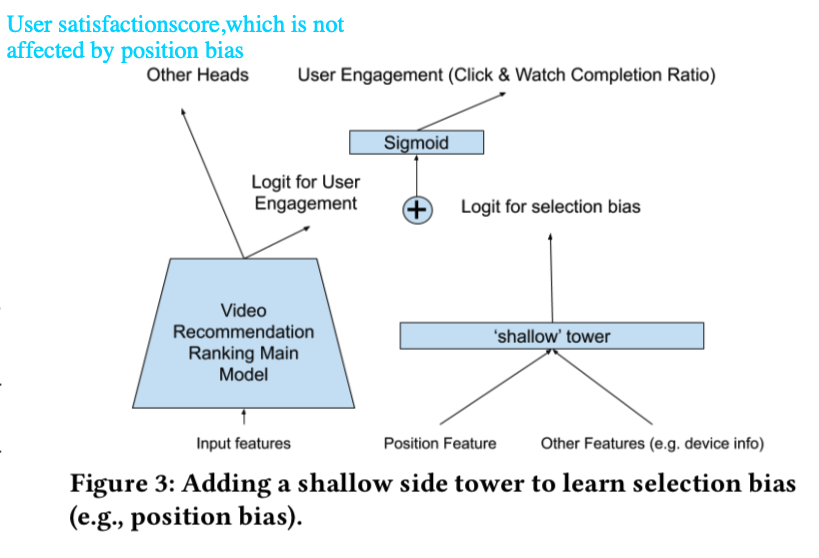
One thing that the paper is not clear about is how to finally use the multi-objective prediction. At the end of Section 4.2, it says:
we take the input of these multiple predictions, and output a combined score using a combination function in the form of weighted multiplication. The weights are manually tuned to achieve best performance on both user engagements and user satisfactions.
But I guess there might be some sweaty work needed to come to the optimal combination.
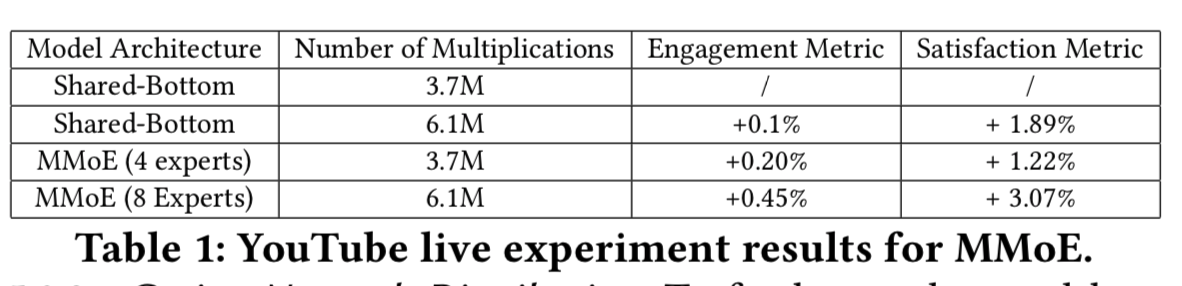
The final result looks pretty good, with improvement in all the metrics:
Since we are talking about position bias, I am interested to see some previous works in battling position bias, which is usually linked to contextual bandit works. The works in position bias and contextual bandit both battle with disproportionate data distribution. While position bias means certain logged samples are either over- or under-represented due to different levels of attention paid to different positions, contextual bandit models try to derive the optimal policy from the data distribution which is generated by sub-optimal policies thus is disproportionate to the data distribution by the optimal policy.
[2] introduces a fundamental framework for learning contextual bandit problems, coined as counterfactual risk minimization (CRM). A good mental model of contextual bandit models is that these models’ outputs are always stochastic and the output distribution keeps updated such that more probable actions should eventually correlate to the ones leading to higher returns.

Note the objective used for batch w/bandit in Table 1. If you look at the paper [2], you’ll know that  is some clipped version of importance sampling-based error:
is some clipped version of importance sampling-based error:
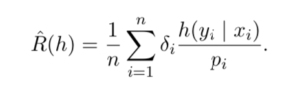
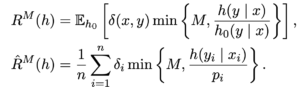
A typical loss function for contextual bandit models would be and [2]’s main contribution is to augment the loss function with  (I need to verify if this sentence is correct). But as [2] suggested, the part
(I need to verify if this sentence is correct). But as [2] suggested, the part  is said to “penalize the hypotheses with large variance during training using a data-dependant regularizer”.
is said to “penalize the hypotheses with large variance during training using a data-dependant regularizer”.
Another sound previous work is [3]. The main idea is that a randomized dataset is used to estimate position bias. The intuition is simple: if you just randomize the order of a model’s ranking output, the click rate at each position would not be affected by any content placed on that content because content effects would be cancelled out by randomization. So the click rate at each position would only be related to the position itself, and that’s exactly position bias.
[4, 5] claims that you can account for position bias through Inverse Propensity Scores (IPS) when you evaluate a new ranking function based on implicit feedback (observable signals like clicks are implicit feedback, while the real user intent is explicit feedback but not always easily obtained). Intuitively, when we collect implicit feedback datasets like click logs, we need to account for observation bias because top positions certainly draw more feedbacks than bottom positions.
The learning-to-rank loss augmented by IPS is:
 ,
,
where  is the rank of an item
is the rank of an item  in the ranked list
in the ranked list  by the new model,
by the new model,  is the logged list,
is the logged list,  denotes what is the probability of observing an item being clicked in the logged data. In the paper, the authors propose to express as the probability of browsing the position of times the probability of clicking on .
denotes what is the probability of observing an item being clicked in the logged data. In the paper, the authors propose to express as the probability of browsing the position of times the probability of clicking on .
Finally, this loss function can be optimized through SVM-Rank [5].
Reference
[1] Recommending What Video to Watch Next: A Multitask Ranking System
[2] Batch Learning from Logged Bandit Feedback through Counterfactual Risk Minimization
[3] Learning to Rank with Selection Bias in Personal Search
[4] Unbiased Learning-to-Rank with Biased Feedback ARXIV
[5] Unbiased Learning-to-Rank with Biased Feedback ICJAI