Evaluating trained RL policies offline is extremely important in real-world production: a trained policy with unexpected behaviors or unsuccessful learning would cause the system regress online therefore what safe to do is to evaluate their performance on the offline training data, based on which we decide whether to deploy. Evaluating policies offline is an ongoing research topic called “counterfactual policy evaluation” (CPE): what would a policy perform even though we only have trajectories that were generated by some other policy?
CPE for contextual bandit
We first look at CPE on contextual bandit problems. The contextual bandit problem is to take action  at each state
at each state  that is drawn from a distribution
that is drawn from a distribution  . We can only observe the reward associated to that specific pair of and :
. We can only observe the reward associated to that specific pair of and :  . Rewards associated to other actions not taken
. Rewards associated to other actions not taken  can’t be observed. The next state at which you would take the next action, will not be affected by the current state or action. Essentially, contextual bandit problems are Markov Decision Problems when horizon (the number of steps) equals one. Suppose we have a dataset
can’t be observed. The next state at which you would take the next action, will not be affected by the current state or action. Essentially, contextual bandit problems are Markov Decision Problems when horizon (the number of steps) equals one. Suppose we have a dataset  with
with  samples, each sample being a tuple
samples, each sample being a tuple  .
.  is sampled from a behavior policy
is sampled from a behavior policy  .
.  is calculated based on an underlying but non-observable reward function
is calculated based on an underlying but non-observable reward function  . For now, we ignore any noise that could exist in reward collection. To simplify our calculation, we will assume that the decision of
. For now, we ignore any noise that could exist in reward collection. To simplify our calculation, we will assume that the decision of  is independent across samples: this assumption bypasses the possible fact that may maintain an internal memory
is independent across samples: this assumption bypasses the possible fact that may maintain an internal memory  , which is the history of observations used to facilitate its future decisions. We will also assume that during data collection we can access the true probability
, which is the history of observations used to facilitate its future decisions. We will also assume that during data collection we can access the true probability  , the true action propensity of the behavior policy. This is not difficult to achieve in practice because we usually have the direct access to the current policy’s model. We will call the policy that we want to evaluate target policy, denoted as
, the true action propensity of the behavior policy. This is not difficult to achieve in practice because we usually have the direct access to the current policy’s model. We will call the policy that we want to evaluate target policy, denoted as  .
.
Given all these notations defined, the value function of is:
![V^{\pi_1} = \mathbb{E}_{s \sim \mathcal{D}, a \sim \pi_1(\cdot|s)}[r(s,a)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-f4a1d1e00e97065f04cbd2ce40b97fbf_l3.png "Rendered by QuickLaTeX.com")
A straightforward way called Direct Method (DM) to estimate  is to train an approximated reward function
is to train an approximated reward function  and plug into :
and plug into :

The bias of directly determines the bias of  . The problem is that if is only trained on generated by , it might be possible that these samples do not sufficiently cover state/action pairs relevant to , thus could be very biased and inaccurate.
. The problem is that if is only trained on generated by , it might be possible that these samples do not sufficiently cover state/action pairs relevant to , thus could be very biased and inaccurate.
The second method is called inverse propensity score (IPS). Its formulation is basically importance sampling on rewards:

We can prove that  is an unbiased estimator of . I get some ideas from [4]:
is an unbiased estimator of . I get some ideas from [4]:
![\mathbb{E}_{p_{\pi_0}(\mathcal{S})}[V^{\pi_1}_{IPS}] \newline (p_{\pi_0}(\mathcal{S}) \text{ is the joint distribution of all samples generated by }\pi_0) \newline = \frac{1}{N}\int p_{\pi_0}(\mathcal{S})\sum\limits_{(s_i, a_i, r_i) \in \mathcal{S}} \frac{r_i \pi_1(a_i|s_i)}{\pi_0(a_i|s_i)} d\mathcal{S} \newline \text{(since each sample is collected independently, we have:)}\newline=\frac{1}{N}\sum\limits_{(s_i, a_i, r_i) \in \mathcal{S}}\int p_{\pi_0}(s_i, a_i)\frac{r(s_i, a_i)\pi_1(a_i|s_i)}{\pi_0(a_i|s_i)}ds_i da_i \newline=\int p_{\pi_0}(s, a)\frac{r(s, a)\pi_1(a|s)}{\pi_0(a|s)}ds da \newline=\int p_\mathcal{D}(s) \pi_0(a|s)\frac{r(s, a)\pi_1(a|s)}{\pi_0(a|s)}dsda \newline=\int p_{\pi_1}(s,a)r(s,a) dsda\newline=V^{\pi_1}](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-bb82f8b47ba652b49135c45939d0b150_l3.png "Rendered by QuickLaTeX.com")
There is one condition to be satisfied for the proof to be hold: if  then
then  . First, we don’t need to worry about that any exists in the denominator of because those samples would never be collected in in the first place. However, if
. First, we don’t need to worry about that any exists in the denominator of because those samples would never be collected in in the first place. However, if  for some
for some  , there would never be data to evaluate the outcome of taking action at state , which means becomes a biased estimator of . (Part of these ideas comes from [7].)
, there would never be data to evaluate the outcome of taking action at state , which means becomes a biased estimator of . (Part of these ideas comes from [7].)
The intuition behind is that:
- If is a large (good) reward, and if
 , then we guess that is probably better than because may give actions leading to good rewards larger probabilities than .
, then we guess that is probably better than because may give actions leading to good rewards larger probabilities than . - If is a small (bad) reward, and if , then we guess that is probably worse than because may give actions leading to bad rewards larger probabilities than .
- We can reverse the relationship such that if
 , we can guess is better than if itself is a bad reward. probably is a better policy trying to avoid actions leading to bad rewards.
, we can guess is better than if itself is a bad reward. probably is a better policy trying to avoid actions leading to bad rewards. - If and is a good reward, is probably a better policy trying to take actions leading to good rewards.
We can also relate the intuition of to Inverse Probability of Treatment Weighting (IPTW) in observational studies [5]. In observational studies, researchers want to determine the effect of certain treatment while the treatment and control selection of subjects is not totally randomized. IPTW is one kind of adjustment to observational data for measuring the treatment effect correctly. One intuitive explanation of IPTW is to weight the subject with how much information the subject could reveal [2]. For example, if a subject who has a low probability to receive treatment and has a high probability to stay in the control group happened to receive treatment, his treatment result should be very informative because he represents the characteristics mostly associated with the control group. In a similar way, we can consider the importance sampling ratio  for each as an indicator of how much information that sample reveals. When the behavior policy neglects some action that is instead emphasized by (i.e.,
for each as an indicator of how much information that sample reveals. When the behavior policy neglects some action that is instead emphasized by (i.e.,  ), the sample
), the sample  has some valuable counter-factual information hence we need to “amplify” .
has some valuable counter-factual information hence we need to “amplify” .
The third method to estimate called Doubly Robust (DR) [1] combines the direct method and IPS method:
![V^{\pi_1}_{DR}=\frac{1}{N}\sum\limits_{(s_i, a_i, r_i) \in \mathcal{S}} \big[\frac{(r_i - \hat{r}(s_i, a_i))\pi_1(a_i|s_i)}{\pi_0(a_i|s_i)} +\int\hat{r}(s_i, a')\pi_1(a'|s_i) da'\big]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-16c1ae79a43158ca6705a023d35b2d8e_l3.png "Rendered by QuickLaTeX.com")
Given our assumption that we know the true action propensity ,  is still an unbiased estimator:
is still an unbiased estimator:
![\mathbb{E}_{p_{\pi_0}(\mathcal{S})}[V^{\pi_1}_{DR}] \newline=\int p_{\pi_0}(s, a) \cdot \big[\frac{(r(s,a) - \hat{r}(s, a))\pi_1(a|s)}{\pi_0(a|s)} +\int \hat{r}(s, a')\pi_1(a'|s) da' \big]ds da \newline=\int p_{\pi_0}(s,a) \cdot\big[\frac{(r(s,a) - \hat{r}(s, a))\pi_1(a|s)}{\pi_0(a|s)} +\int(\hat{r}(s, a') - r(s,a'))\pi_1(a'|s)da' +\int r(s, a')\pi_1(a'|s)da' \big] dsda\newline=\int p_{\pi_1}(s,a) \cdot (-1+1)dsda + \int p_{\pi_1}(s,a) r(s,a) dsda\newline=V^{\pi_1}](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-5b2eddcbd24d5f73844ceadc1403863d_l3.png "Rendered by QuickLaTeX.com")
However, in the original paper of DR [1], the authors don’t assume that the true action propensity can be accurately obtained. This means, can be a biased estimator: however, if or have biases under certain bounds, would have far lower bias than either of the other two.
Under the same assumption that the true action propensity is accessible, we could get the variances of DM, DR, and IPS CPE (![Var[V^{\pi_1}_{DM}]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-12aee5da684ae437aa1a26c635fd139b_l3.png "Rendered by QuickLaTeX.com") ,
, ![Var[V^{\pi_1}_{DR}]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-8e13f1d57c52b4dffceb24ccea350b4d_l3.png "Rendered by QuickLaTeX.com") , and
, and ![Var[V^{\pi_1}_{IPS}]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-b5322ee77892dbe58ae427c62ac99361_l3.png "Rendered by QuickLaTeX.com") ) based on the formulas given in Theorem 2 in [1] while setting
) based on the formulas given in Theorem 2 in [1] while setting  because we assume we know the true action propensity:
because we assume we know the true action propensity:
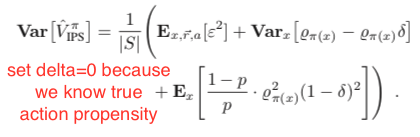
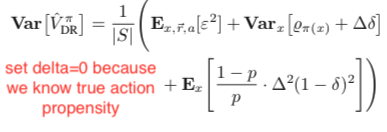
![]()
Under some reasonable assumptions according to [1], should be between and . Therefore, should be overall favored because of its zero bias and intermediate variance.
CPE for MDP
We have completed introducing several CPE methods on contextual bandit problems. Now, we move our focus to CPE on Markov Decision Problems when horizon is larger than 1. The value function of a policy is:
![V^{\pi} = \mathbb{E}_{s_0 \sim \mathcal{D}, a_t \sim \pi(\cdot|s_t), s_{t+1}\sim P(\cdot|a_t, s_t)}[\sum\limits_{t=1}^H\gamma^{t-1}r_t],](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-bfc55bc4eff25229d7795708eb741006_l3.png "Rendered by QuickLaTeX.com")
where  is the number of steps in one trajectory. Simplifying the notation of this formula, we get:
is the number of steps in one trajectory. Simplifying the notation of this formula, we get:
![V^{\pi} = \mathbb{E}_{\tau \sim (\pi, \mu)}[R(\tau)],](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-e5c9a9a941f327d049ea0a128cc6e56f_l3.png "Rendered by QuickLaTeX.com")
where  is a single trajectory,
is a single trajectory,  denotes the transition dynamics,
denotes the transition dynamics,  is the accumulative discounted rewards for the trajectory .
is the accumulative discounted rewards for the trajectory .
Following the idea of IPS, we can have importance-sampling based CPE of based on trajectories generated by :


 is an unbiased estimator of given the same condition satisfied in : if then .
is an unbiased estimator of given the same condition satisfied in : if then .  is also an unbiased estimator of proved in [6]. However, has lower upper bound than therefore in practice usually enjoys lower variance than (compare chapter 3.5 and 3.6 in [9]).
is also an unbiased estimator of proved in [6]. However, has lower upper bound than therefore in practice usually enjoys lower variance than (compare chapter 3.5 and 3.6 in [9]).
Following the idea of DR, [3] proposed unbiased DR-based CPE on finite horizons, and later [8] extended to the infinite-horizon case:

where  and
and  are the learned q-value and value function under the behavior policy .
are the learned q-value and value function under the behavior policy .  and we define the corner case
and we define the corner case  .
.
Based on Theorem 1 in [3], should have lower variance than ![Var[V^{\pi_1}_{per-decision-IS}]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-b0bf550ee2c92e20f6b532ef1f593f34_l3.png "Rendered by QuickLaTeX.com") , after realizing that per-decision-IS CPE is a special case of DR CPE.
, after realizing that per-decision-IS CPE is a special case of DR CPE.
Another CPE method also proposed by [6] is called Weighted Doubly Robust (WDR). It normalizes  in :
in :

where  .
.
 is a biased estimator but since it truncates the range of
is a biased estimator but since it truncates the range of  in to
in to ![[0,1]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-3c2f548a134dfa658b30df58bb768060_l3.png "Rendered by QuickLaTeX.com") , WDR could lower variance than DR when fewer samples are available. The low variance of WDR produces larger reduction in expected square error than the additional error incurred by the bias. (See chapter 3.8 of [9]). Furthermore, under reasonable assumptions WDR is a consistent estimator so the bias will become less an issue as the sample size increase. (As a side note, an estimator can be any combination of biased/unbiased and inconsistent/consistent [10].)
, WDR could lower variance than DR when fewer samples are available. The low variance of WDR produces larger reduction in expected square error than the additional error incurred by the bias. (See chapter 3.8 of [9]). Furthermore, under reasonable assumptions WDR is a consistent estimator so the bias will become less an issue as the sample size increase. (As a side note, an estimator can be any combination of biased/unbiased and inconsistent/consistent [10].)
Direct Method CPE on trajectories learns to reconstruct the MDP. This means DM needs to learn the transition function and reward function for simulating episodes.The biggest concern is whether the collected samples support to train a low bias model. If they do, then DM can actually achieve very good performance. [8] Section 6 lists a situation when DM can outperform DR and WDR: while DM has a low variance and low bias (even no bias), stochasticity of reward and state transition produces high variance in DR and WDR.
The last CPE method is called Model and Guided Importance Sampling Combining (MAGIC) [8]. It is considered as the best CPE method because it adopts the advantages from both WDR and DM. The motivation given by [8] is that CPE methods involving importance sampling are generally consistent (i.e., when samples increase, the estimated distribution moves close to the true value) but still suffer high variance; model-based methods (DM) has low variance but is biased. MAGIC combines the ideas of DM and WDR such that MAGIC can track the performance of whichever is better between DM and WDR. The MAGIC method is heavily math involved. Without deep dive into it yet, we only show its pseudocode for now:

Below is a table concluding this post, showing whether each CPE method (for evaluating trajectories) is biased/unbiased and consistent/inconsistent.
| DM | biased | inconsistent | 1 |
| trajectory-IS | unbiased | consistent | 5 |
| per-decision-IS | unbiased | consistent | 4 |
| DR | unbiased | consistent | 3 |
| WDR | biased | consistent | 2 |
| MAGIC | biased | consistent | Not sure, possibly
between 1 and 2 |
(Table note: (1) variance rank 1 means the lowest variance, 5 means the highest; (2) when generating this table, we use some reasonable assumptions we mentioned and used in the papers cited .)