Policy Generalist
Deepmind has recently published a work named Gato. I find it interesting as Gato learns a multi-modal multi-task policy to many tasks such as robot arm manipulation, playing atari, and image captioning. I don’t think the original paper [2] has every detail of implementation but I’ll try to best summarize what I understand. I will also try to survey literature pertinent to Gato because it can be very useful towards the north star of general AI.
First of all, Gato adopts the most common architecture these days – transformers. The core idea is to transform data of different modalities into sequences of tokens. Then tokens will be passed through embedding tables or some model-based transformation to generate embeddings of the same embedding dimension.
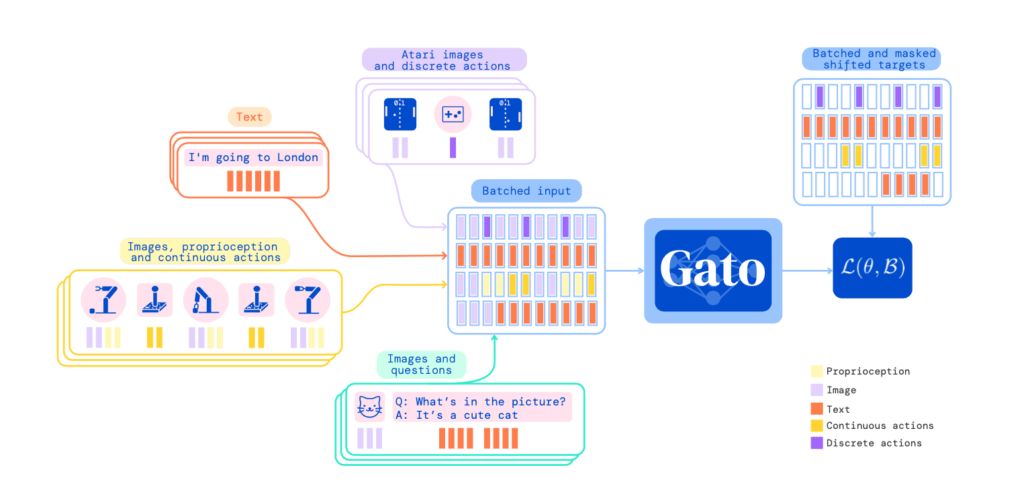
Here is how different modalities are sequentialized. Texts data are natural sequences of words. Each word (or phrase) will be indexed with a unique integer. Image data will be transformed into non-overlapping 16×16 patches in raster order. Reinforcement learning tasks will generate sequences of tuples (observation, action). They don’t include reward in sequences because (I guess) they mainly use behavior cloning/imitation learning. Specifically, they pick from the top-performing expert demonstration sequences and use supervised learning to fit expert actions. Continuous actions are discretized into discrete actions. For image patches, the authors applied ResNet to generate their embeddings. For texts/actions, they are passed through learnable embedding tables to generate their embeddings.
If you pay attention, you will find that all different kinds of tasks have a discrete action space. As we mentioned earlier, reinforcement learning tasks have either discrete actions or continuous actions that are transformed into discrete actions. For chatbot/image captioning tasks, the action space is basically the vocabulary space. So the training loss used by Gato can be just autoregressive cross-entropy:
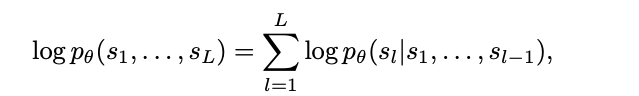
Algorithm Distillation
Algorithm distillation is a novel idea to me at first glance [3]. But I can relate to works a few years ago about learning to learn using RNN [4, 5]. The idea of [3] is that when we solve a reinforcement learning task or multiple RL tasks using an algorithm of our interest, we can record (state, action, reward) sequences that span multiple episodes. When these multi-episode sequences are long enough, they contain information about how the algorithm improves the policy over time and how the policy being improved interacted with the environment(s). We can train a sequence model (e.g., transformers) to directly mimic the multi-episode sequences. As a result, the RL algorithm itself is distilled into the sequence model. We can then call the sequence model on a new task and asks it to just unroll itself. The sequence model will magically unroll actions that can gradually improve returns over time, just like we use the training RL algorithm on a new task!

References
[1] DeepMind Gato Explained – One AI Model for 600 tasks https://www.youtube.com/watch?v=EEcxkv60nxM
[2] A Generalist Agent https://arxiv.org/abs/2205.06175
[3] In-context Reinforcement Learning with Algorithm Distillation: https://arxiv.org/abs/2210.14215
[4] Learning to Learn without Gradient Descent by Gradient Descent: https://arxiv.org/abs/1611.03824
[5] Learning to learn by gradient descent by gradient descent: https://proceedings.neurips.cc/paper/2016/file/fb87582825f9d28a8d42c5e5e5e8b23d-Paper.pdf