In my rough understanding, inverse reinforcement learning is a branch of RL research in which people try to perform state-action sequences resembling given tutor sequences.
There are two famous works on inverse reinforcement learning. One is Apprenticeship Learning via Inverse Reinforcement Learning [1], and the other is Maximum Margin Planning [2].
Maximum Margin Planning
In MMP learn a cost function for estimating the cost at each state-action pair. The desired cost function should emit low costs to those state-action pairs appearing in “tutor” sequences (examples) and return high costs to those deviating tutor sequences. If we manage to recover a desired cost function, we can assign the cost for any state-action pair and use path-finding algorithms (e.g., A*, Dijkstra, etc.) to find a sequence on a new environment which has the minimum accumulative sum of costs, that is, a sequence deemed resembling given tutor sequences.
The baisc idea is given in [4]:

As you see, in line 6, you need to adjust cost function to increase on the current “not-perfect” minimum cost path and decrease the example path. However, you can see that the algorithm doesn’t know how much it should increase the cost for minimum cost path. If one path just deviates from the example path a little bit and another path deviates far more abnormally, how should the adjustment of the cost function reflect that?
So the author proposes an improvement called “loss augmentation”. Suppose the original cost at a state-action is  , then we say its augmented cost
, then we say its augmented cost  , where
, where  is a loss function with large values for those deviated state-action pairs and with close-to-zero values for those resembling tutor sequences. Why do we want the augmented cost to be even smaller for those defiant state-action pairs? Because in this way, we make those deviated pairs even harder to be distinguished with the desired pairs. Therefore, we force the algorithm to try hard to update the cost function until it can differentiate augmented costs from different state-action pairs. In other words, the algorithm will learn the cost function such that it differentiates any a desired state-action pair
is a loss function with large values for those deviated state-action pairs and with close-to-zero values for those resembling tutor sequences. Why do we want the augmented cost to be even smaller for those defiant state-action pairs? Because in this way, we make those deviated pairs even harder to be distinguished with the desired pairs. Therefore, we force the algorithm to try hard to update the cost function until it can differentiate augmented costs from different state-action pairs. In other words, the algorithm will learn the cost function such that it differentiates any a desired state-action pair  with a less desired state-action pair
with a less desired state-action pair  by at least a margin
by at least a margin  .
.
Here is the visualization showing how deviated paths get high rewards (+1) and desired paths get low rewards (-1).
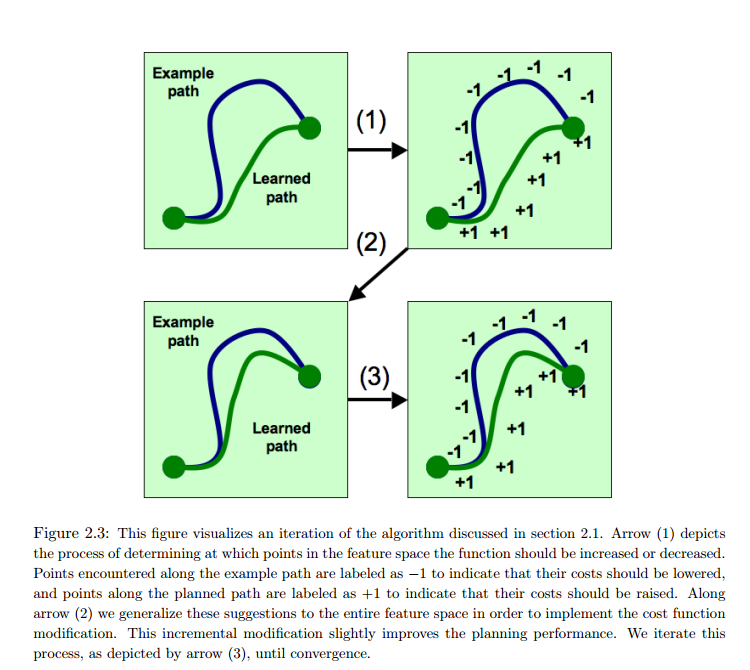
And here is the revised algorithm based on Algorithm 1:

Now, let’s look at how to learn the cost function using a framework called maximum margin structured classification.
Before that, we introduce preliminaries. In this paper, we are given  examples, each example is a MDP and a tutor sequence. Different examples may come from different MDPs so this model can learn the cost function generalized to new MDPs which are never seen in the training examples. However, for simplicity, we just assume all training examples are different tutor sequences from the same MDP with state
examples, each example is a MDP and a tutor sequence. Different examples may come from different MDPs so this model can learn the cost function generalized to new MDPs which are never seen in the training examples. However, for simplicity, we just assume all training examples are different tutor sequences from the same MDP with state  and
and  . For simplicity purpose also, an important assumption made throughout [4] is that a tutor sequence is acyclic. This means, any state-action pair is visited at most once in a tutor sequence. Then, it is easy to represent a tutor sequence by
. For simplicity purpose also, an important assumption made throughout [4] is that a tutor sequence is acyclic. This means, any state-action pair is visited at most once in a tutor sequence. Then, it is easy to represent a tutor sequence by  , a state-action frequency count vector. If the assumption about tutor sequence being acyclic were not made,
, a state-action frequency count vector. If the assumption about tutor sequence being acyclic were not made,  which satisfies certain flow constraints.
which satisfies certain flow constraints.
Now remember that the idea is to approximate everything linearly, such as the loss function or the cost function. Each training example has a loss function, which quantifies the difference between an arbitrary sequence and  -th example tutor sequence
-th example tutor sequence  . Since we want loss function to be a linear function of
. Since we want loss function to be a linear function of  , we let
, we let  . The more deviates from , the higher
. The more deviates from , the higher  should be. A straightforward way to define
should be. A straightforward way to define  is to make
is to make  , with 0 denoting a particular state-action is visited by both or neither of and and 1 otherwise. Of course more advanced loss function can be used but the bottom line is to assume
, with 0 denoting a particular state-action is visited by both or neither of and and 1 otherwise. Of course more advanced loss function can be used but the bottom line is to assume  . Now as for cost function, cost function should also factor over states and actions. This means, the cost of a sequence should be the sum of the costs at each state-action pairs visited in the sequence. Suppose we have a feature matrix
. Now as for cost function, cost function should also factor over states and actions. This means, the cost of a sequence should be the sum of the costs at each state-action pairs visited in the sequence. Suppose we have a feature matrix  , whose columns are feature vectors at every state-action pair. We also suppose the cost function has a linear weight
, whose columns are feature vectors at every state-action pair. We also suppose the cost function has a linear weight  . Then, the cost at one state-action pair is just
. Then, the cost at one state-action pair is just  where
where  is the column corresponding to the state-action pair. Finally, the cost of the whole sequence is
is the column corresponding to the state-action pair. Finally, the cost of the whole sequence is  . You can think
. You can think  as the accumulated sum of feature vectors on visited state-action pairs.
as the accumulated sum of feature vectors on visited state-action pairs.
Since we assume all training examples come from the same MDP, we can write the data set as  .
.
Now, the problem is how to obtain  . Recall that we want to be able to differentiate desired paths ( from
. Recall that we want to be able to differentiate desired paths ( from  ) from tentative paths (arbitrary
) from tentative paths (arbitrary  , where
, where  is all possible sequence in the MDP) by a margin . Therefore, the constraints we would like to impose are: for each , for each ,
is all possible sequence in the MDP) by a margin . Therefore, the constraints we would like to impose are: for each , for each ,  . This actually introduces a large number of constraints when space is large. Therefore, we reduce the number of constraints by rewriting as: for each ,
. This actually introduces a large number of constraints when space is large. Therefore, we reduce the number of constraints by rewriting as: for each ,  . Intuitively, this means if can successfully distinguish from the loss-augmented cost of the hardest tentative path , then it can distinguish from any other tentative paths. Also, we would like to regularize on the norm of because if were without norm regularization, it can always scale arbitrarily large to overcome margin difference constraints, voiding the original purpose of adding margins. Moreover, we want to introduce a slack term
. Intuitively, this means if can successfully distinguish from the loss-augmented cost of the hardest tentative path , then it can distinguish from any other tentative paths. Also, we would like to regularize on the norm of because if were without norm regularization, it can always scale arbitrarily large to overcome margin difference constraints, voiding the original purpose of adding margins. Moreover, we want to introduce a slack term  for each training example. This allows some margin difference constraints to not be satisfied because in real data you may not find a which perfectly satisfies all margin difference constraints.
for each training example. This allows some margin difference constraints to not be satisfied because in real data you may not find a which perfectly satisfies all margin difference constraints.
Putting all we describe above, we come to the optimization objective:

We note that  resides in both the objective function and the constraints. We want as small as possible. Therefore, at the minimizer the slack variables will always exactly equal the constraint violation:
resides in both the objective function and the constraints. We want as small as possible. Therefore, at the minimizer the slack variables will always exactly equal the constraint violation:  . Therefore, we can rewrite our constrained objective function into another non-constrained objective function:
. Therefore, we can rewrite our constrained objective function into another non-constrained objective function:

Now,  is a non-differentiable (because of
is a non-differentiable (because of  ), convex objective. The author in [4] proposes to optimize using subgradient method.
), convex objective. The author in [4] proposes to optimize using subgradient method.
In my mind, subgradient method is really similar to normal gradient descend method. The gradient  of a differentiable convex function
of a differentiable convex function  at point
at point  satisfies:
satisfies:  . This means the growth of line
. This means the growth of line  from point is always equal or slower than
from point is always equal or slower than  [7]:
[7]:
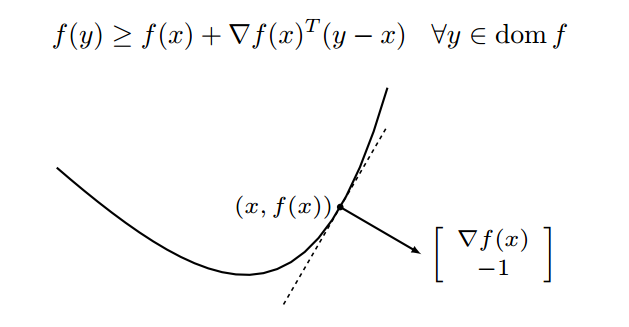
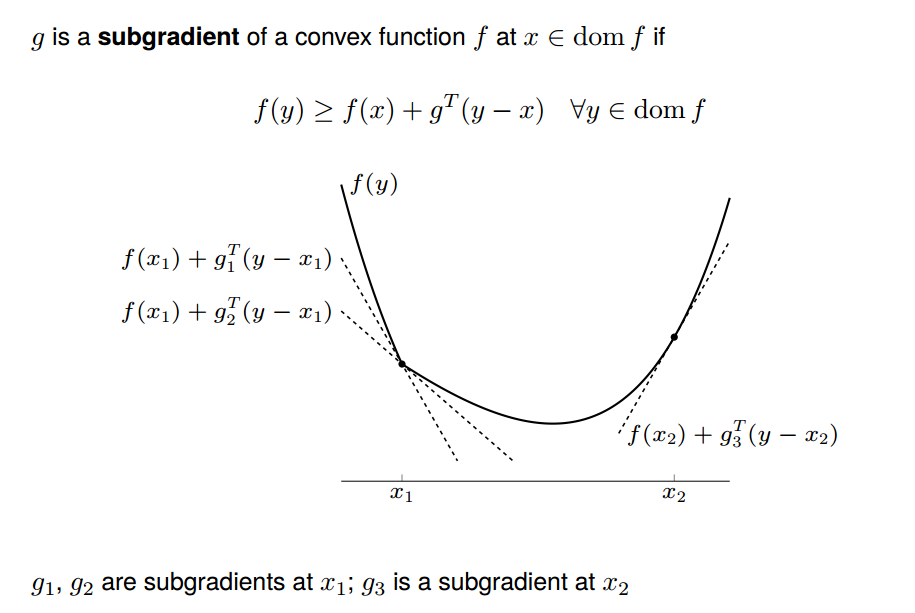
Subgradient equal to gradient at the part being differentiable. At the non-differentiable part, subgradient  can be any values such that
can be any values such that  :
:
Now let’s look at the part  in . This part can be rewritten as
in . This part can be rewritten as  . This can be seen as a max over affine functions
. This can be seen as a max over affine functions  , each shown as dashed line the figure below:
, each shown as dashed line the figure below: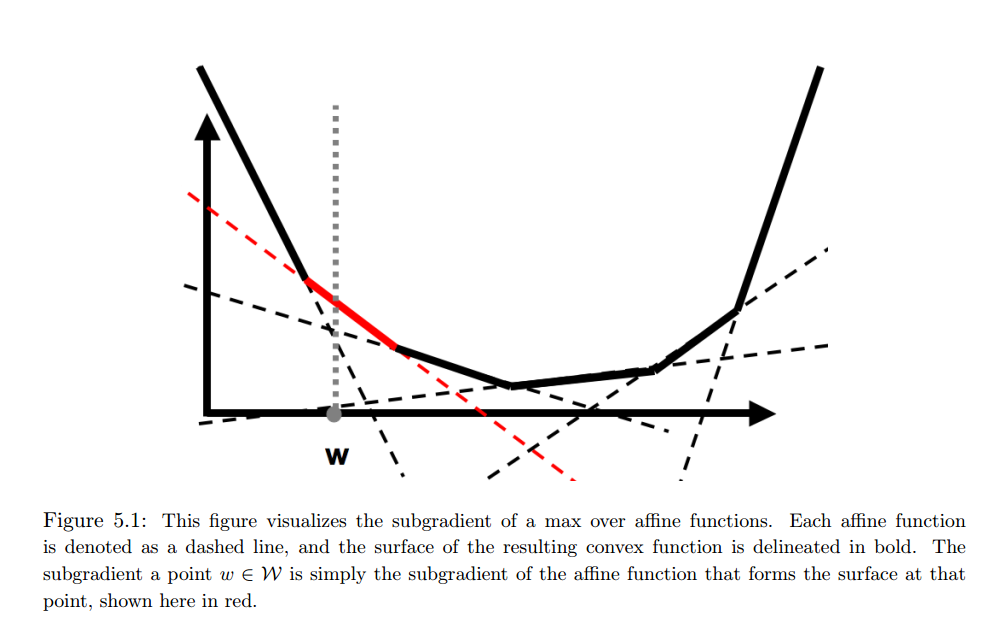
The bold line is . The red line is the subgradient at specific value of marked by the vertical dashed line. Therefore, the subgradient of is:

where  .
.
Now, can be updated online, i.e., being updated after seeing example one by one:
![w_{t+1} = \mathcal{P}_{\mathcal{W}} [ w_t - \alpha (F(\mu_i - \mu_i^*) + \lambda w_t)] &s=2](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-da1f9da44bb49e5a8b49cb87a57eeaed_l3.png "Rendered by QuickLaTeX.com")
where  is projection operator that maps to feasible region. For example, sometimes we even require all costs should be positive. How to do projection is something I don’t fully understand in [4]. I hope I will illustrate once I am crystal clear about that.
is projection operator that maps to feasible region. For example, sometimes we even require all costs should be positive. How to do projection is something I don’t fully understand in [4]. I hope I will illustrate once I am crystal clear about that.
Reference
[1] Apprenticeship Learning via Inverse Reinforcement Learning
[3] Boosting Structured Prediction for Imitation Learning
[4] Learning to Search: Structured Prediction Techniques for Imitation Learning (Ratliff’s thesis)
[5] Max Margin Learning (Youtube video)
[6] Max Margin Planning Slides
2018.4.8
Seems like this is a good tutorial (https://thinkingwires.com/posts/2018-02-13-irl-tutorial-1.html) for explaining [8]