In reinforcement learning (RL), it is common that a task only reveals rewards sparsely, e.g., at the end of an episode. This prevents RL algorithms from learning efficiently, especially when the task horizon is long. There has been some research on how to distribute sparse rewards to more preceding steps.
One simple, interesting research is [1]. Its loss is defined as: The loss can be understood as that each step’s reward
The loss can be understood as that each step’s reward  constitutes contribution from the current state
constitutes contribution from the current state  and all previous states
and all previous states  , gated by
, gated by  .
.
[7] uses Transformers (or any attention-based sequence models) to decompose episode reward to step rewards. The loss function is: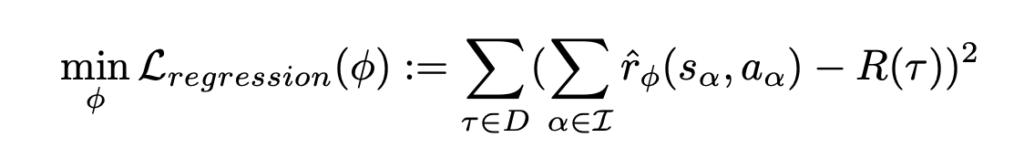 You can think of
You can think of  in the subscript of
in the subscript of  and
and  as
as  , i.e., the Transformers will take into accounts all previous steps until the current step to make the prediction of reward for the current step. The difference with [1] is that: a. [7] uses previous steps’ information more effectively using a sequence model; b. [7] only decomposes the total episode reward
, i.e., the Transformers will take into accounts all previous steps until the current step to make the prediction of reward for the current step. The difference with [1] is that: a. [7] uses previous steps’ information more effectively using a sequence model; b. [7] only decomposes the total episode reward  , while [1] decomposes for every step reward.
, while [1] decomposes for every step reward.
Another research is Hindsight Experience Replay (HER) [4], in which we create spurious but easier-to-achieve rewards. This repository has a clear implementation [5].
HER is best explained using an example, a bit-flipping environment, as described below: As you can see, this environment could have
As you can see, this environment could have  states and only one state could give you a positive reward. It would almost be infeasible for a normal RL model to explore and learn effectively. What confused me but now is clear to me is that the state of this environment fed to an RL model has two parts, the current
states and only one state could give you a positive reward. It would almost be infeasible for a normal RL model to explore and learn effectively. What confused me but now is clear to me is that the state of this environment fed to an RL model has two parts, the current  bits and the target bits. This is manifested in the agent’s learn function in [5].
bits and the target bits. This is manifested in the agent’s learn function in [5].
The crux of HER is as follows. Even when an episode terminates and fails, we augment the replay buffer with some new tuples, pretending that we want to arrive the last state as the target goal.
Because of these intermediate easier goals being attached to the state, the RL model has more non-sparse experience to learn from to reach the goal specified in its state.
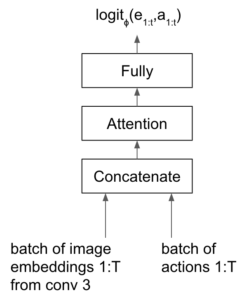
Finally, there is work called Temporal Value Transport [8], with a blog [9] explaining it. I think this work is very heuristic-driven. Suppose one episode has  steps, they use a sequence model with attention mechanism to predict each pair of steps
steps, they use a sequence model with attention mechanism to predict each pair of steps  ‘s influence on reward (
‘s influence on reward ( ). Specifically, the sequence model is a classifier predicting whether “the logit predicting whether the rewards-to-go from a given observation are below or above a threshold.” (from [9]).
). Specifically, the sequence model is a classifier predicting whether “the logit predicting whether the rewards-to-go from a given observation are below or above a threshold.” (from [9]).
Then, the reward is re-distributed by:


Below is two works that I do not understand fully.
The first is [6]. It converts the normal policy gradient update:
to:
where  contains the future part of the trajectory after time step
contains the future part of the trajectory after time step  . The intuition that in off-policy learning, we can utilize the steps after the current step to make better value estimation. However, I do not understand how is computed (the paper says it is from a classifier based on RNN) and what
. The intuition that in off-policy learning, we can utilize the steps after the current step to make better value estimation. However, I do not understand how is computed (the paper says it is from a classifier based on RNN) and what  represents.
represents.
The second is RUDDER [2], with its web-view blog explaining it [3]. However, I still do not get it how LSTM is used in RUDDER to distribute rewards. [1]’s related work sheds some lights on how RUDDER works, though:

References
[1] Synthetic Returns for Long-Term Credit Assignment: https://arxiv.org/pdf/2102.12425.pdf
[2] RUDDER: Return Decomposition for Delayed Rewards https://arxiv.org/pdf/1806.07857.pdf
[3] https://ml-jku.github.io/rudder/
[4] Hindsight Experience Replay: https://arxiv.org/pdf/1707.01495.pdf
[5] https://github.com/hemilpanchiwala/Hindsight-Experience-Replay
[6] COUNTERFACTUAL CREDIT ASSIGNMENT IN MODEL-FREE REINFORCEMENT LEARNING: https://arxiv.org/pdf/2011.09464.pdf
[7] Sequence modeling of temporal credit assignment for episodic reinforcement learning: https://arxiv.org/pdf/1905.13420.pdf
[8] Optimizing agent behavior over long time scales by transporting value: https://www.nature.com/articles/s41467-019-13073-w.pdf