Sequential decision problems can usually be formatted as Markov Decision Problems (MDPs), where you define states, actions, rewards and transitions. In some practical problems, states can just be described by action histories. For example, we’d like to decide notification delivery sequences for a group of similar users to maximize their accumulated clicks. We define two actions, whether to send or not send a notification to a user. We can define each user’s state as his or her history of notification receiving. For example, user A might receive a notification at day 1 and day 2 but stop receiving any at day 3, while user B might receive notifications in a row in all the three days. It’s a natural sequential decision problem in which future notification sending decisions depend on different user states. User A might receive a notification on day 4 because he or she hasn’t got one in day 3, while user B will need a notification break on day 4. Sure, one can define state with personal information of a user. But as I just mention, these are similar users with similar backgrounds, preferences, and cultures, and we want to keep things as simple as possible. You get my idea.
You can manually define state feature vectors by encoding action histories. Back to the notification example, you can define features like how many notifications one has received in last 3 days, last week, or last month. However, this may be manually tedious. Alternatively, you can generate some sort of user embedding from action histories. And then policy learning (RL algorithms) would just work on a MDP with user embeddings as states.
That’s why I would like to test LSTM + DQN (Long short-term memory + Deep Q Network). The idea is that at a state, LSTM will take as inputs the user action history so far and output an embedding. That embedding is used as the state to feed into DQN, which tries to approximate Q(s,a). The weights of LSTM and DQN will be jointly learned when fitting Q(s,a).
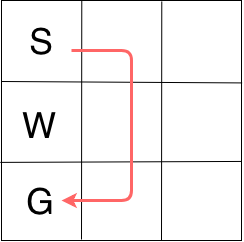
I design two gridworlds to test this idea. Both share the same structure, an agent starts at (0,0), there is some cell that is a wall (unwalkable). The gold state is at the left bottom corner. Whenever the agent enters the gold state, the episode terminates and get rewards 10. Since the reward discount factor will be set to be less than 1, the agent will not only need to get to the gold state, but get it as soon as possible. The difference between the two grid worlds is that the second gridworld endows additional reward plus the gold reward: the agent receives an additional reward at the gold state depending on the action history (the path). Some paths have higher rewards than others.
So the first gridworld (called “finite”) looks like below, with the red line indicates the optimal route.
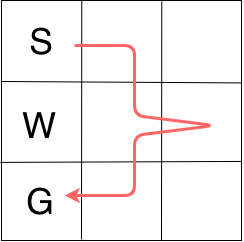
The second gridworld (called “rnn”) looks like below, with the red line indicates the optimal route. It is not simply the shortest path, because going a little zigzag obtains higher rewards.
I test LSTM + DQN and pure DQN. In pure DQN, the state is just a one-hot encoding of which cell the agent is at. Therefore you can imagine pure DQN should fall short in the “rnn” gridworld because the state has no information about past paths. In LSTM + DQN, the state is the hidden layer output of LSTM resulting from the action history passing through LSTM. My test script can be found in Tutorials/action_state_generation/tests/test_online_train.py in this repository. (The file structure may change in the future.)
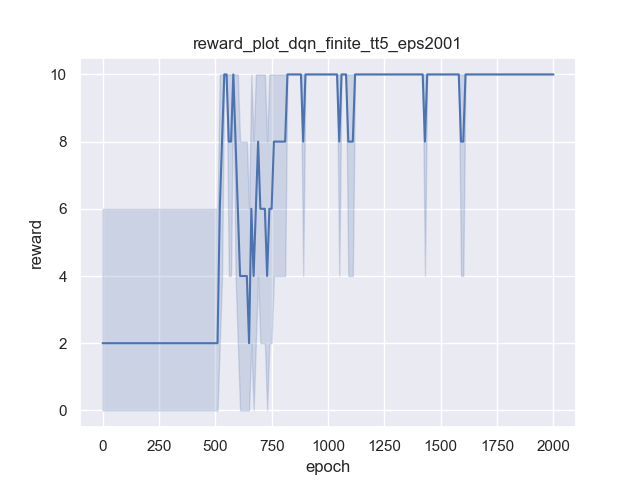
On finite gridworld
Pure DQN:
LSTM+DQN
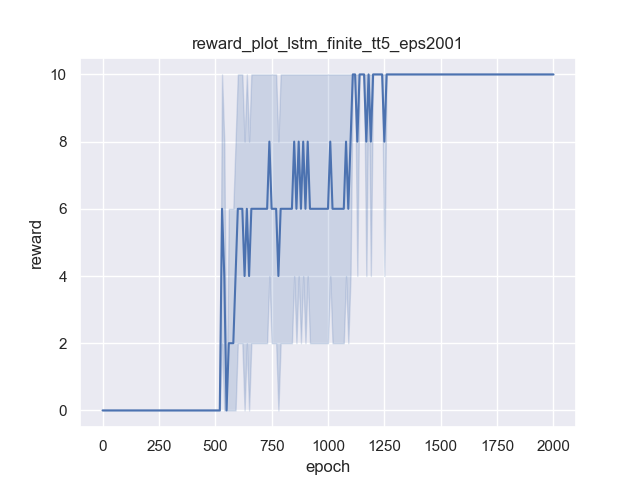
The x-axis is learning epochs, while the y-axis is the final reward. Both algorithms can get the optimal reward 10. I also checked to confirm that they reach reward 10 using just 4 steps. However, you can observe that LSTM+DQN takes longer to converge (in other words, LSTM+DQN is less data efficient). This is as expected because LSTM needs more iterations to understand the sequences and consequences. Recall that the pure DQN encodes grid cells as states directly, while the state in LSTM is just action history. So LSTM needs many iterations to understand how action histories map to which exact cells in the grid.
On rnn gridworld
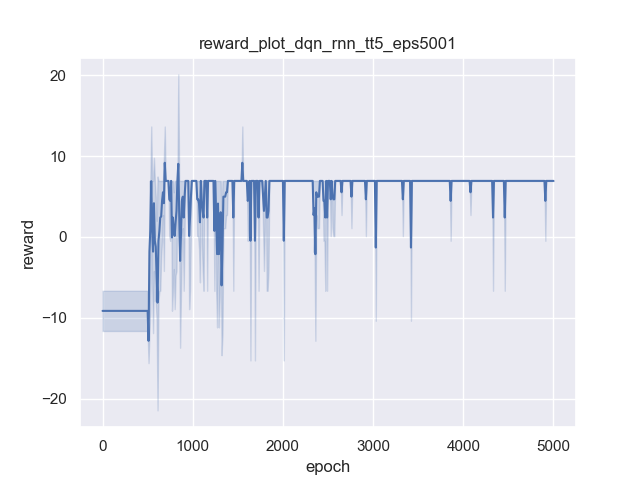
Pure DQN
LSTM+DQN
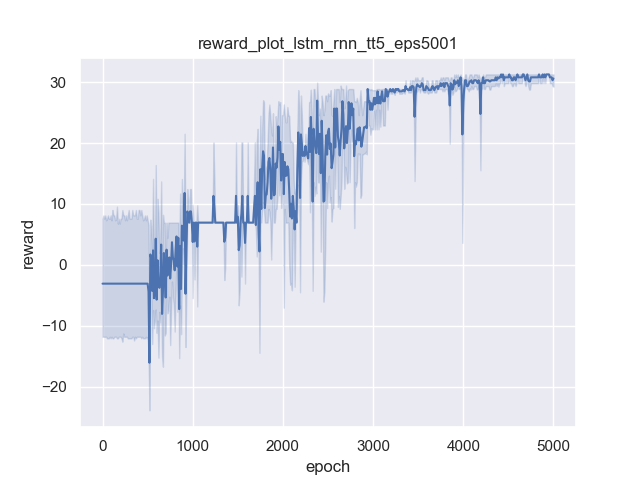
As expected, pure DQN does not reach high rewards at the end because its states do not have historical information. But LSTM+DQN could continuously improve its rewards, simply because the state is LSTM’s hidden state which encodes historical information along action histories.