Original paper: http://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf
Cons and pros on Quora: https://www.quora.com/Reviews-of-Google-File-System
Paper discussion: http://pages.cs.wisc.edu/~swift/classes/cs736-fa08/blog/2008/11/the_google_file_system.html
A blog discussion: http://kaushiki-gfs.blogspot.com/
A ppt discussion: http://www.slideshare.net/tutchiio/gfs-google-file-system
A QA series: http://pages.cs.wisc.edu/~thanhdo/qual-notes/fs/fs4-gfs.txt
GFS wiki: http://google-file-system.wikispaces.asu.edu/
2.3
GFS uses one-master-mutiple-chunkservers mode. Client will query the master about the metadata of files, which reside in the master’s memory hence query is fast. The real data operation takes place at chunkservers. The client can cache metadata of chunkservers so interaction with the master can be reduced.
2.5
A relative large chunk size (64MB) can reduce interaction with the master further: many read/write can happen on the same chunk and network overhead can be reduced by “keeping a persistent TCP connection to the chunkserver over an extended period of time”. The only shortage happens when small executable files, usually taking only one chunk, are requested from many clients at the same time and thus pressure the few chunk servers. Imagine the normal usage case, where a large file usually takes several chunks. Different clients may access different chunks therefore no particular chunk servers become overloaded.
2.7
GFS has a relaxed consistency model. GFS guarantees that: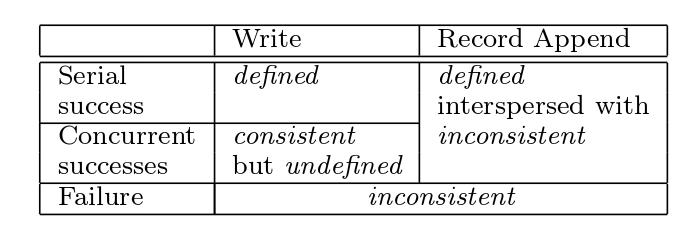 For example, `Record Append` make sure the content to be appended will be appended at least once. The append offset is chosen by GFS to be at the end of the file but not fixed as in normal POSIX. In most cases, after concurrent successes of `Record Append`, the file region will be defined, i.e. all users can see the same content which have already had all their contents appended. Application should deal with duplication or any other inconsistency itself: http://www.cs.cornell.edu/courses/cs6464/2009sp/lectures/15-gfs.pdf. Also from Section 3 you will know that GFS uses leases to ensure that all replicas execute mutations in the same order to achieve consistency.
For example, `Record Append` make sure the content to be appended will be appended at least once. The append offset is chosen by GFS to be at the end of the file but not fixed as in normal POSIX. In most cases, after concurrent successes of `Record Append`, the file region will be defined, i.e. all users can see the same content which have already had all their contents appended. Application should deal with duplication or any other inconsistency itself: http://www.cs.cornell.edu/courses/cs6464/2009sp/lectures/15-gfs.pdf. Also from Section 3 you will know that GFS uses leases to ensure that all replicas execute mutations in the same order to achieve consistency.
That means, GFS is not transparent to applications. Applications need to deal with duplication and validity of data.
4.1 Namespace Management and Locking
You first need to know read lock and write lock:
http://www.coderanch.com/t/418888/java-EJB-SCBCD/certification/Difference-Read-Lock-Write-Lock
https://en.wikipedia.org/wiki/Readers%E2%80%93writer_lock
In a nutshell, write lock can only be acquired exclusively. Read lock can be acquired concurrently by many clients.
There is no per-directory data structure in GFS. With prefix compression (something like we see from information theory), the whole namespace tree is loaded in memory. Each node in the namespace tree has an associated read-write lock. The paper gives the following example to illustrate how locks are acquired when two operations, snapshot and file creation, happen at the same time:

Note that snapshot operation needs to get write lock of `/home/user` because during the snapshot you can’t let other client to get any lock of `/home/user`. For example, if another client can get read lock of `/home/user`, then if it subsequently gets a write lock of `/home/user/foo`, it can create files `/home/user` during `/home/user` is being snapshotted. In the consequence, there might be data inconsistency between `/home/user` and `/save/user`.
At the end
Actually I get very vague design information from the paper. I guess it is because I have shallow knowledge in large distributed system design. I will come back and update this post in the future. Let me use one slide from others to conclude it now:
