Total Accepted: 56706Total Submissions: 180315Difficulty: Medium
Given a linked list, return the node where the cycle begins. If there is no cycle, return null.
Note: Do not modify the linked list.
Follow up: Can you solve it without using extra space?
Idea
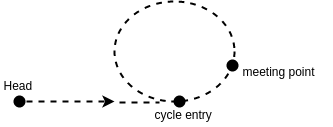
As the plot shows, we have a linked list with a cycle. Suppose it has 1-based index. Head has index `h`. The entry of the cycle has index `e`. We reuse the code from the previous code in which we have a slow pointer and a fast pointer (traversing the list twice as fast as the slow pointer.) The point where the fast and the slow pointer meet has index `m`. We also set the length of the cycle as C.
When the fast and the slow pointers meet:
the number of the nodes the slow pointer has passed: e + (m-e) + n1*C
the number of the nodes the fast pointer has passed: e + (m-e) + n2*C
We also know that 2(e+(m-e)+n1*C) = e+(m-e)+n2*C, because the fast pointer travels twice as fast as the slow pointer.
By canceling same terms on both sides of the equation, we finally get:
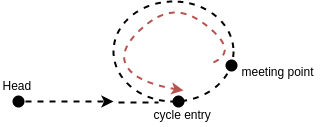
e = C-(m-e) + n3*C
where n3 is a non-negative integer unknown and unimportant to us. C-(m-e) is the distance between the meeting point and the cycle entry along the direction of the linked list. (See the red path in the plot below).
Now it becomes easy to find the value of `e`. You now create a new pointer, `p`, starting from head. Let the slow pointer and `p` travel one node by one node until the two meets. The point where they meet should be the entry of the cycle.
Code
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def detectCycle(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
if not head:
return None
slow = fast = head
while fast.next and fast.next.next:
slow = slow.next
fast = fast.next.next
if slow == fast: # Find cycle
p = head
while p != slow:
p = p.next
slow = slow.next
return slow
return None
Total Accepted: 25004Total Submissions: 87854Difficulty: Medium
Find the kth largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.
For example, Given [3,2,1,5,6,4] and k = 2, return 5.
Note: You may assume k is always valid, 1 ≤ k ≤ array’s length.
Code 1 (Using partition idea from quicksort with O(N) / O(N^2) time complexity on average/ worst case and O(1) space. Please see reference on complexity analysis.)
class Solution(object):
def findKthLargest(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: int
"""
if not nums:
return -1
left, right = 0, len(nums)-1
while True:
pos = self.partition(nums, left, right)
if pos == k-1:
return nums[pos]
elif pos < k-1:
left = pos+1
else:
right = pos-1
def partition(self, nums, left, right):
# always pick nums[left] as pivot
pivot = nums[left]
p1, p2 = left+1, right
while p1 <= p2:
if nums[p1]<pivot and nums[p2]>pivot:
nums[p1], nums[p2] = nums[p2], nums[p1]
p1, p2 = p1+1, p2-1
if nums[p1] >= pivot:
p1 += 1
if nums[p2] <= pivot:
p2 -= 1
nums[left], nums[p2] = nums[p2], nums[left]
return p2
s = Solution()
print s.findKthLargest([7,6,5,4,3,2,1], 5)
The function `partition` puts the numbers smaller than `nums[left]` to its left and then returns the new index of `nums[left]`. The returned index is actually telling us how small `nums[left]` ranks in nums.
Code 2 (Using a heap of size k with O(NlogK) time complexity and O(K) space complexity. ):
from heapq import *
class Solution(object):
def findKthLargest(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: int
"""
if not nums:
return -1
h = []
for i in xrange(len(nums)):
if len(h) < k:
heappush(h, nums[i])
else:
if h[0] < nums[i]:
heappop(h)
heappush(h, nums[i])
return h[0]
Idea
In Python heapq, heap is a min-heap. Therefore, h[0] is always the smallest element in the heap and heappop always pops the smallest element. heappop and heappush takes O(logK) time complexity therefore the total time bound is O(NlogK).
Our problem is given a matrix costs in which costs[i][j] is the traveling cost going from node i to node j, we are asked to return the minimum cost for traveling from node 0 and visit every other node exactly once and return back to node 0.
We use g(x, S) to denote the minimum cost for a travel which starts from node x, visits every node in S exactly once and returns to node 0. The detailed DP process can be illustrated in the following example.
Let’s say we have a 5×5 costs matrix, which means we have 5 node.
In the first round, we calculate:
g(1, ∅) = costs(1,0) # minimum cost of travel from node 1 and ends at node 0 without visiting any other node
g(2, ∅) = costs(2,0)
g(3, ∅) = costs(3,0)
g(4, ∅) = costs(4,0)
In the second round, we calculate:
# minimum cost of travel from node 1 and ends at node 0 with visiting only one other node
g(1, {2}) = costs(1,2) + g(2, ∅)
g(1, {3}) = costs(1,3) + g(3, ∅)
g(1, {4}) = costs(1,4) + g(4, ∅)
# minimum cost of travel from node 2 and ends at node 0 with visiting only one other node
...
In the third round, we calculate:
# minimum cost of travel from node 1 and ends at node 0 with visiting two other nodes
g(1, {2,3}) = min(costs(1,2)+g(2,{3}), costs(1,3)+g(3,{2})) # either you choose to go from 1 to 2 first, or go from 1 to 3 first
g(1, {3,4}) = min(costs(1,3)+g(3,{4}), costs(1,4)+g(4,{3}))
g(1, {2,4}) = min(costs(1,2)+g(2,{4}), costs(1,4)+g(4,{2}))
# minimum cost of travel from node 2 and ends at node 0 with visiting two other nodes
...
In the fourth round, we calculate:
# minimum cost of travel from node 1 and ends at node 0 with visiting three other nodes
# either you choose to go from 1 to 2 first, or go from 1 to 3 first or go from 1 to 4 first
g(1, {2,3,4}) = min(costs(1,2)+g(2,{3,4}), costs(1,3)+g(3,{2,4}), costs(1,4)+g(4,{2,3}))
# minimum cost of travel from node 2 and ends at node 0 with visiting three other nodes
...
After the four rounds above, we can calculate our ultimate goal, g(0, {1,2,3,4}):
from itertools import *
class Solution:
def shortest(self, costs):
'''
costs: List[List[n]]
'''
def to_str(l):
return '-'.join([str(ll) for ll in l])
# nodes excluding the starting node
nodes = set([i for i,v in enumerate(costs) if i])
g = {}
for x in xrange(1, len(costs)):
g[x] = {}
g[x][''] = costs[x][0]
for k in xrange(1, len(costs)-1):
for x in xrange(1, len(costs)):
for c in combinations(node-set([x]), k):
g[x][to_str(c)] = min([costs[x][e] + g[e][to_str(c-set([e]))] for e in c])
return min([costs[0][e] +g[e][to_str(nodes-set([e]))] for e in nodes])
In the code `g` is a dictionary. Its value its another dictionary. For example, if we want to refer to g(1, {2,3,4}), we can access it by `g[1][‘2-3-4’]`.
Let’s analyze the time complexity and the space complexity for this DP algorithm.
Space complexity: before calculating g(0, {1,2,3,4}), we need to store:
Therefore, for each row here, we need to store g(.) values of number $latex \sum\limits_{k=1}^{n-2} C_{n-1}^k = O(2^n) $ (n is total number of nodes: 0, 1, .., n-1). We have n-1 rows here. So in total space complexity is $latex O(n2^n)$.
Time complexity: we know we have $latex O(n2^n)$ g(.) values to store. We get each of these values by taking min function over O(n) possible candidates(See Python code line 20). Therefore, the total time complexity is $latex O(n^2 2^n)$.
Total Accepted: 4861Total Submissions: 13934Difficulty: Medium
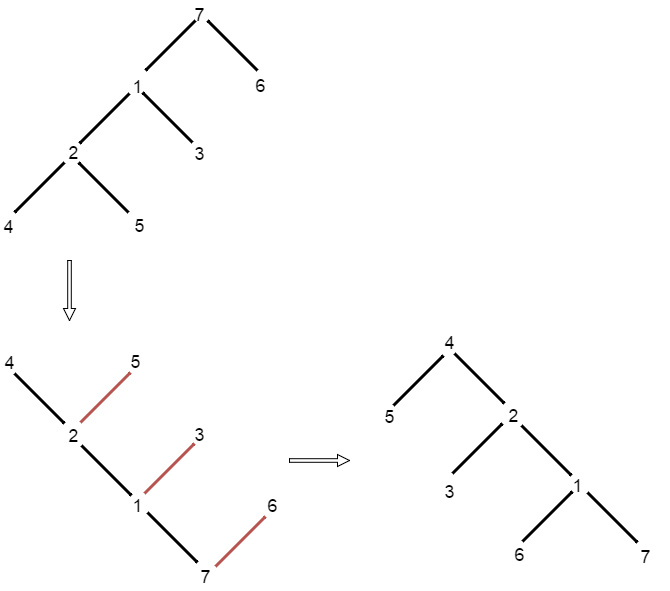
Given a binary tree where all the right nodes are either leaf nodes with a sibling (a left node that shares the same parent node) or empty, flip it upside down and turn it into a tree where the original right nodes turned into left leaf nodes. Return the new root.
For example: Given a binary tree {1,2,3,4,5},
1
/ \
2 3
/ \
4 5
return the root of the binary tree [4,5,2,#,#,3,1].
The serialization of a binary tree follows a level order traversal, where ‘#’ signifies a path terminator where no node exists below.
Here’s an example:
1
/ \
2 3
/
4
\
5
The above binary tree is serialized as "{1,2,3,#,#,4,#,#,5}".
Code
class Solution:
# @param root, a tree node
# @return root of the upside down tree
def upsideDownBinaryTree(self, root):
# take care of the empty case
if not root:
return root
# take care of the root
l = root.left
r = root.right
root.left = None
root.right = None
# update the left and the right children, form the new tree, update root
while l:
newL = l.left
newR = l.right
l.left = r
l.right = root
root = l
l = newL
r = newR
return root
Idea
First, let’s walk through what is called “upside down”. I draw an example plot. The original tree roots at 7. To turn it upside down, you first mirror it along a horizontal line. Then, for any branch stretching towards right top (marked as red), you make it as left leaf.
Now, the basic idea is to go though from the original root (7), make root’s left child (1) as new parent whose left child will be the original root’s right left (6) and right child will be the original root (7). After that, you set new root to root.left (1), and process it in the same way. As pointed out by (https://leetcode.com/discuss/18410/easy-o-n-iteration-solution-java), the core idea is to “Just think about how you can save the tree information you need before changing the tree structure“.
Total Accepted: 76404Total Submissions: 229965Difficulty: Hard
Given a binary tree, return the postorder traversal of its nodes’ values.
For example: Given binary tree {1,#,2,3},
1
\
2
/
3
return [3,2,1].
Note: Recursive solution is trivial, could you do it iteratively?
Idea:
This problem is similar to a previous post. However, it can be done using a property regarding preorder and postorder: postorder traverse = reverse of {preorder traverse with right node visited earlier than left node}.
The detailed implementation: modify the previous post code. You still do a preorder traverse but with the order: [root], [right], [left]. To do so, when you push to the stack, you push node.left first then push node.right. So when you pop the stack, you will visit the right node first then sometimes later the left node. At last, when you return the `res` list, you return its reverse.
In practice you have two choices, either always append values to `res` left, or use normal append but return `res[::-1]`.
Code
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
# An alternative: append left to res
# def postorderTraversal(self, root):
# st = [root]
# res = []
# while st:
# root = st.pop()
# if root:
# res.insert(0,root.val)
# st.append(root.left)
# st.append(root.right)
# return res
def postorderTraversal(self, root):
st = [root]
res = []
while st:
root = st.pop()
if root:
res.append(root.val)
st.append(root.left)
st.append(root.right)
return res[::-1]
Total Accepted: 89130Total Submissions: 240451Difficulty: Medium
Given a binary tree, return the preorder traversal of its nodes’ values.
For example: Given binary tree {1,#,2,3},
1
\
2
/
3
return [1,2,3].
Note: Recursive solution is trivial, could you do it iteratively?
Code
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def preorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
stack = [root]
res = []
while stack:
node = stack.pop()
if node:
res += [node.val]
stack.append(node.right)
stack.append(node.left)
return res
Idea
Preorder: [root], [left], [right]
So we use a stack to add right first then left. so whenever we pop an element out, the left element will always be popped out before the right element. Since we want to return preorder result, whenever an element is popped out, we add it to `res` immediately.
Total Accepted: 30832Total Submissions: 81197Difficulty: Easy
Given a binary search tree (BST), find the lowest common ancestor (LCA) of two given nodes in the BST.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes v and w as the lowest node in T that has both v and w as descendants (where we allow a node to be a descendant of itself).”
For example, the lowest common ancestor (LCA) of nodes 2 and 8 is 6. Another example is LCA of nodes 2 and 4 is 2, since a node can be a descendant of itself according to the LCA definition.
Code
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def lowestCommonAncestor(self, root, p, q):
"""
:type root: TreeNode
:type p: TreeNode
:type q: TreeNode
:rtype: TreeNode
"""
if p.val > q.val:
p, q = q, p
if p.val < root.val and q.val > root.val:
return root
if p.val == root.val or q.val == root.val:
return root
if p.val < root.val and q.val < root.val:
return self.lowestCommonAncestor(root.left, p, q)
else:
return self.lowestCommonAncestor(root.right, p, q)
Idea
Since it is already a BST, it should be easy. Please go to another post to see how to find lowest common ancestor for normal binary tree.