Bayesian Network Augmented Naive-Bayes (BAN) is an improved version of Naive-Bayes, in which every attribute  may have at most one other attribute as its parent other than the class variable
may have at most one other attribute as its parent other than the class variable  . For example (figure from [1]):
. For example (figure from [1]):
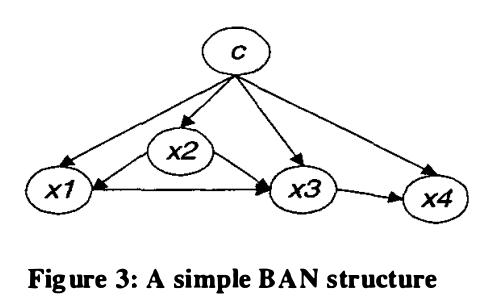
Though BAN provides a more flexible structure compared to Naive Bayes, the structure (i.e., dependence/independence relationships between attributes) needs to be learnt. [2] proposed a method using a scoring function called Minimum Description Length (MDL) for structure learning. Basically, given training data set  , you start from a random network structure
, you start from a random network structure  and calculate its
and calculate its  . We set the current best network structure
. We set the current best network structure  . Then for any other possible structure
. Then for any other possible structure  , is set to
, is set to  if
if  . As you can see, we want to find a network structure which can minimize MDL(g|D).
. As you can see, we want to find a network structure which can minimize MDL(g|D).
Now let’s look at the exact formula of  :
:

The second term of , which is the negative LogLikelihood of  given data , is easy to understand. Given the data , we would like the likelihood of such structure as large as possible. Since we try to minimize , we write it in a negative log likelihood format. However, merely using the negative LogLikelihood(g|D) as a scoring function is not enough, since it strongly favors the structure to be too sophisticated (a.k.a, overfitting). That is why the first term
given data , is easy to understand. Given the data , we would like the likelihood of such structure as large as possible. Since we try to minimize , we write it in a negative log likelihood format. However, merely using the negative LogLikelihood(g|D) as a scoring function is not enough, since it strongly favors the structure to be too sophisticated (a.k.a, overfitting). That is why the first term  comes into place to regulate the overall structure:
comes into place to regulate the overall structure:
 is the number of parameters in the network.
is the number of parameters in the network.  is the size of dataset.
is the size of dataset.  is the length of bits to encode every parameter. So penalizes the networks with many parameters. Taking for example the network in the figure above, suppose attribute
is the length of bits to encode every parameter. So penalizes the networks with many parameters. Taking for example the network in the figure above, suppose attribute  has two possible values, i.e.,
has two possible values, i.e.,  . Similarly,
. Similarly,  ,
,  ,
,  , and
, and  . Then attribute
. Then attribute  can have
can have  combinations of values. Further, we can use one more parameter to represent the joint probability of
combinations of values. Further, we can use one more parameter to represent the joint probability of  , one minus which is the joint probability of
, one minus which is the joint probability of  . Hence
. Hence  . Why we can use bits to encode each parameter? Please refer to section 2 in [3] and my reading note on that at the end of this post.
. Why we can use bits to encode each parameter? Please refer to section 2 in [3] and my reading note on that at the end of this post.
Back to [2], you can find in the paper that the negative likelihood functino in  is replaced by mutual information format. Such transformation is equivalent and was proved in [4].
is replaced by mutual information format. Such transformation is equivalent and was proved in [4].
My reading note on Section 2 in [3]
Until equation (3), the author is just describing the context. Not too hard to understand. Equation (3) basically says there are  number of the parameters in the network. This is exactly what I explained two paragraphs earlier.
number of the parameters in the network. This is exactly what I explained two paragraphs earlier.
Then, the author gave equation (4) (5) (6):

Here,  is a vector of length
is a vector of length  . Each component of vector is noted as
. Each component of vector is noted as ![\theta[q,s,g]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-ba246c3dbb92dca4ba3457bb825a3593_l3.png "Rendered by QuickLaTeX.com") , which refers to the conditional probability of observing
, which refers to the conditional probability of observing  and
and  given a model . For a given network ,
given a model . For a given network , ![\sum_{q}\sum_{s}\theta[q,s,g] =1](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-10d362620c363ec91a63621edf3e193e_l3.png "Rendered by QuickLaTeX.com") .
.
Then,  is the prior distribution of the vector . The author supposes it is a Dirichlet distribution, thus equals to:
is the prior distribution of the vector . The author supposes it is a Dirichlet distribution, thus equals to:

For any possible value , the posterior probability is  . The real marginal probaiblity of
. The real marginal probaiblity of  is to integrate over all possible values:
is to integrate over all possible values:
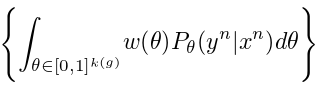
Then the author said the description length of  is just to take negative log as in equation (4). I don’t quite get it at this point. What I can think of is that the negative log likelihood is perfect for its monotonically decreasing property. The higher probability of , the more desirable the structure is. Since we want to minimize MDL anyway, why not just assign MDL to such negative log format?
is just to take negative log as in equation (4). I don’t quite get it at this point. What I can think of is that the negative log likelihood is perfect for its monotonically decreasing property. The higher probability of , the more desirable the structure is. Since we want to minimize MDL anyway, why not just assign MDL to such negative log format?
Then the author claimed that:
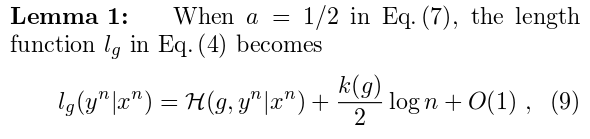
This is why we can use bits to encode each parameter.
Reference
[1] Cheng, J., & Greiner, R. (1999, July). Comparing Bayesian network classifiers. In Proceedings of the Fifteenth conference on Uncertainty in artificial intelligence (pp. 101-108). Morgan Kaufmann Publishers Inc..
[2] Hamine, V., & Helman, P. (2005). Learning optimal augmented Bayes networks. arXiv preprint cs/0509055.
[3] Suzuki, J. (1999). Learning Bayesian belief networks based on the minimum description length principle: basic properties. IEICE transactions on fundamentals of electronics, communications and computer sciences, 82(10), 2237-2245.
[4] Friedman, N., Geiger, D., & Goldszmidt, M. (1997). Bayesian network classifiers. Machine learning, 29(2-3), 131-163.
Other references, though not used in the post, are useful in my opinion:
[5] De Campos, L. M. (2006). A scoring function for learning bayesian networks based on mutual information and conditional independence tests. The Journal of Machine Learning Research, 7, 2149-2187.
[6] Rissanen, J. (1978). Modeling by shortest data description. Automatica, 14(5), 465-471.
[7] Liu, Z., Malone, B., & Yuan, C. (2012). Empirical evaluation of scoring functions for Bayesian network model selection. BMC bioinformatics, 13(Suppl 15), S14.