I am reading this paper (https://arxiv.org/abs/1801.01290) and wanted to take down some notes about it.
Introduction
Soft Actor-Critic is a special version of Actor-Critic algorithms. Actor-Critic algorithms are one kind of policy gradient methods. Policy gradient methods are different than value-based methods (like Q-learning), where you learn Q-values and then infer the best action to take at each state  using
using  . Policy gradient methods do not depend on value functions to infer the best policy, instead they directly learn a probability function
. Policy gradient methods do not depend on value functions to infer the best policy, instead they directly learn a probability function  . However policy gradient methods may still learn value functions for the purpose of better guiding the learning of the policy probability function .
. However policy gradient methods may still learn value functions for the purpose of better guiding the learning of the policy probability function .
We have introduced several kinds of policy gradient methods in [2, 18]. Here, we briefly recap. The objective function of policy gradient methods is:
 ,
,
where  is the parameter of the policy
is the parameter of the policy  .
.
In problems with a discrete action space, we can rewrite the expectation in summation:

where  is the stationary distribution of Markov chain for ,
is the stationary distribution of Markov chain for , ![V^\pi(s)=\mathbb{E}_{a \sim \pi}[G_t|S_t=s]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-81e80918e8ee5ee716538d3fd9167787_l3.png "Rendered by QuickLaTeX.com") , and
, and ![Q^{\pi}(s,a)=\mathbb{E}_{a \sim \pi}[G_t|S_t=s, A_t=a]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-fb78793408bc59dde51b8ee271d116f6_l3.png "Rendered by QuickLaTeX.com") .
.  is accumulated rewards since time step
is accumulated rewards since time step  :
:  .
.
Policy gradient methods strive to learn the values of , which is achieved through gradient ascent w.r.t.  . The gradient
. The gradient  is obtained by the policy gradient theorem (proved in [4]):
is obtained by the policy gradient theorem (proved in [4]):
![\nabla_\theta J(\theta) = \mathbb{E}_{s,a\sim\pi}[Q^\pi(s,a)\nabla_\theta log \pi_\theta(a|s)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-2beb309a8f7f851c92dbb14d57dfb021_l3.png "Rendered by QuickLaTeX.com")
Different policy gradient methods use different methods to estimate  : REINFORCE uses a Monte Carlo method in which empirical accumulated rewards is used to unbiasedly approximate ; state-value actor-critic learns a value function
: REINFORCE uses a Monte Carlo method in which empirical accumulated rewards is used to unbiasedly approximate ; state-value actor-critic learns a value function  and uses
and uses  to approximate ; action-value actor-critic learns a Q-value function
to approximate ; action-value actor-critic learns a Q-value function  and uses
and uses  to approximate . Note that since is in an expectation form
to approximate . Note that since is in an expectation form ![\mathbb{E}_{s,a \sim \pi} [\cdot]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-5f964b41e5266ad100f51f229146af14_l3.png "Rendered by QuickLaTeX.com") , we need to collect on-policy samples. That’s why the soft actor-critic papers mentions in Introduction:
, we need to collect on-policy samples. That’s why the soft actor-critic papers mentions in Introduction:
“some of the most commonly used deep RL algorithms, such as TRPO, PPO, A3C, require new samples to be collected for each gradient step.”
If we have only off-policy samples instead, which are collected by  , becomes “the value function of the target policy, averaged over the state distribution of the behavior policy” (from DPG paper [19]):
, becomes “the value function of the target policy, averaged over the state distribution of the behavior policy” (from DPG paper [19]):
![J(\theta)=\mathbb{E}_{s\sim \pi_b} \left[ \mathbb{E}_{a\sim\pi}Q^{\pi}(s,a) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-87a3d46598262d6296e094b4f0577e4f_l3.png "Rendered by QuickLaTeX.com")
The critical problem presented by this formula is that if you take derivative of w.r.t. , you’d better to be able to write the gradient without ![\mathbb{E}_{a\sim\pi}[\cdot]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-ae63a6ea8b6c194261a8601712a0ab95_l3.png "Rendered by QuickLaTeX.com") because any such gradient can’t be computed using mini-batches collected from . Rather, we have several choices to learn given this off-policy objective :
because any such gradient can’t be computed using mini-batches collected from . Rather, we have several choices to learn given this off-policy objective :
- Using importance sampling, rewrite
![\mathbb{E}_{a\sim\pi}\left[ Q^{\pi}(s,a)\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-786220bca35e8ded97c42aa993eea6f2_l3.png "Rendered by QuickLaTeX.com") as
as ![\mathbb{E}_{a\sim\pi_b}\left[\frac{\pi(a|s)}{\pi_b(a|s)}Q^{\pi_b}(s,a) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-3c2b92f89489c602968842cc5519c476_l3.png "Rendered by QuickLaTeX.com") . This results to the gradient update
. This results to the gradient update ![\mathbb{E}_{s,a \sim \pi_b} [\frac{\pi(a|s)}{\pi_b(a|s)} Q^{\pi_b}(s,a) \nabla_\theta log \pi(a|s)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-e53e8508268cfd534fe9b14611870dd4_l3.png "Rendered by QuickLaTeX.com") . See [18]. However, importance sampling can cause great variance empirically.
. See [18]. However, importance sampling can cause great variance empirically. - Making the policy deterministic would remove the expectation . then becomes
![J(\theta)=\mathbb{E}_{s\sim\pi_b}\left[Q^{\pi}(s,\pi(s))\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-1104f775b9ace7162e169ed09964c019_l3.png "Rendered by QuickLaTeX.com") . The gradient update can be computed as
. The gradient update can be computed as ![\mathbb{E}_{s\sim \pi_b}\left[ \nabla_\theta \pi(s) \nabla_a Q^\pi(s,a)|_{a=\pi(s)}\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-80844574a104283d7e501a74060dc13b_l3.png "Rendered by QuickLaTeX.com") . This is how DPG works. See [20].
. This is how DPG works. See [20]. - Using reparametrization trick (covered more below), which makes
 , a deterministic function plus an independent noise, we would have
, a deterministic function plus an independent noise, we would have ![J(\theta)=\mathbb{E}_{s\sim\pi_b, \epsilon \sim p_\epsilon}\left[Q^{\pi}(s,\pi(s))\right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-786969025c9166246b593b6c0aab5fd0_l3.png "Rendered by QuickLaTeX.com") . The gradient update would be:
. The gradient update would be: ![\mathbb{E}_{s\sim\pi_b, \epsilon \sim p_\epsilon}\left[\nabla_a Q^{\pi}(s,a)|_{a=\pi(s)} \nabla_\theta \pi(s) \right] \newline=\mathbb{E}_{s\sim\pi_b, \epsilon \sim p_\epsilon}\left[\nabla_a Q^{\pi}(s,a)|_{a=\pi(s) } \nabla_\theta \pi^{deterministic}(s) \right]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-3e7b7d028abc02800aecea0e7c0aa695_l3.png "Rendered by QuickLaTeX.com")
The third method is used in Soft Actor-Critic, although SAC adds some more ingredients. Let’s now dive into it.
Soft Actor-Critic
Soft Actor-Critic (SAC) is designed to be an off-policy policy-gradient method. What makes it special is that it strives to maximize long-term rewards as well as action randomness, because more random actions mean better exploration and robustness. Therefore, in the maximum entropy framework, the objective function can be formulated as:
![\[ J(\pi)=\sum\limits^T_{t=0}\mathbb{E}_{(s_t, a_t)\sim\rho_\pi} \left[r(s_t, a_t) + \alpha \mathcal{H} \left( \pi\left(\cdot | s_t \right) \right) \right], \]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-5423cd8c98adcc2ea0804f071ecc8266_l3.png "Rendered by QuickLaTeX.com")
where  of an action distribution
of an action distribution  is the entropy defined as
is the entropy defined as ![\mathbb{E}_{a \sim \pi(\cdot|s_t)}[-log \pi(a|s)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-880d8a6d23e8e39d4ae342a2a93bd4db_l3.png "Rendered by QuickLaTeX.com") , and
, and  is the term controlling the influence of the entropy term.
is the term controlling the influence of the entropy term.
We can always treat  by subsuming it into the reward function. Therefore, with omitted, we have the following objective function, soft Q-function update operator, and soft value function:
by subsuming it into the reward function. Therefore, with omitted, we have the following objective function, soft Q-function update operator, and soft value function:
(1) ![\[ J(\pi)=\sum\limits^T_{t=0}\mathbb{E}_{(s_t, a_t)\sim\rho_\pi} \left[r(s_t, a_t) + \mathcal{H} \left( \pi\left(\cdot | s_t \right) \right) \right] \]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-4a6cf3d3915c59fcec26e955409380eb_l3.png "Rendered by QuickLaTeX.com")
(2) ![\[ \mathcal{T}^\pi Q(s_t, a_t) \triangleq r(s_t, a_t) + \gamma \mathbb{E}_{s_{t+1}\sim p}\left[V(s_{t+1})\right] \]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-471e4ff56f93a3edf8422b21a37dd645_l3.png "Rendered by QuickLaTeX.com")
(3) ![\[ V(s_t) = \mathbb{E}_{a_t \sim \pi}\left[Q(s_t, a_t) - \log \pi(a_t|s_t) \right] \]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-a9bacc02a46af7eea5da40a110dae030_l3.png "Rendered by QuickLaTeX.com")
Derivation
The paper uses Lemma1, Lemma 2 and Theorem 1 to prove the learning pattern will result in the optimal policy that maximizes the objective in Eqn. (1). The tl; dr is that Lemma1 proves that soft Q-values of any policy would converge rather than blowing up; Lemma2 proves that based on a policy’s soft Q-values, you can find a no-worse policy.
Lemma 1 proof

“The standard convergence results for policy evaluation” means:
(1) there exists a fixed point  because of the way we define Eqn.15: for each state and each action
because of the way we define Eqn.15: for each state and each action  , we define one equation of Eqn.15. We have
, we define one equation of Eqn.15. We have  equations in total. And there are dimensions of . Therefore, there exists a unique fixed point:
equations in total. And there are dimensions of . Therefore, there exists a unique fixed point:  , where
, where  is the operator for calculating expectation
is the operator for calculating expectation ![\mathbb{E}[\cdot]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-eff568ea1582b23954f9a75fe3009a12_l3.png "Rendered by QuickLaTeX.com") .
.
(2) prove  is a
is a  -contraction under the infinity norm, i.e.,
-contraction under the infinity norm, i.e.,  . Explained in plain English, being a -contraction means consecutive application of make the function
. Explained in plain English, being a -contraction means consecutive application of make the function  closer to the fixed point at the rate of .
closer to the fixed point at the rate of .
The proof is found from [6]:

The last two steps are derived using  from [7] and the fact that
from [7] and the fact that  (because is the operator for , though I have not verified this fact though).
(because is the operator for , though I have not verified this fact though).
(3) therefore, by contraction theory (Theorem 5.1-2 in [10]), applying will eventually lead to . [9]
Convergence of policy evaluation/value evaluation usually have the similar pattern, such as the one for Q-learning [8].
Lemma 2 proof

Proving Lemma 2 is basically just expanding  -divergence formula
-divergence formula  . From Eqn. 16, we expand -divergence formula as:
. From Eqn. 16, we expand -divergence formula as:
![J_{\pi_{old}}(\pi'(\cdot|s_t)) \newline \triangleq D_{KL} (\pi'(\cdot | s_t) \; \Vert \; exp(Q^{\pi_{old}}(s_t, \cdot) - \log Z^{\pi_{old}}(s_t)) ) \newline = - \int \pi'(a_t | s_t) \log \frac{exp(Q^{\pi_{old}}(s_t, a_t) - \log Z^{\pi_{old}}(s_t)))}{\pi'(a_t|s_t)} d a_t \newline = \int \pi'(a_t | s_t) \big(\log \pi'(a_t|s_t) + \log Z^{\pi_{old}}(s_t) - Q^{\pi_{old}}(s_t, a_t) ) \big) d a_t \newline = \mathbb{E}_{a_t \sim \pi'}[\log \pi'(a_t|s_t) + \log Z^{\pi_{old}}(s_t) - Q^{\pi_{old}}(s_t, a_t) )]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-9326b886e89c908e7b8a582c210605dd_l3.png "Rendered by QuickLaTeX.com")
Note that the authors defined a new objective function  , which is different than Eqn.1. The purpose of defining
, which is different than Eqn.1. The purpose of defining  is to help us get to Eqn. 18, which is then used to prove
is to help us get to Eqn. 18, which is then used to prove  in Eqn. 19.
in Eqn. 19.
Implementation
Since we are looking at cases with continuous actions, the authors suppose we use a network to output mean and standard deviation for a (multi-dimensional) Gaussian. In other words, this network has an output vector for action means  , and another output vector for action standard deviations
, and another output vector for action standard deviations  . The action that is to be taken will be sampled from
. The action that is to be taken will be sampled from  .
.

Since ![D_{KL}(p\Vert q) = \mathbb{E}_{x \sim p(x)}[\log p(x) - \log q(x)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-23d5ad1f4496452366a1d22e5299f373_l3.png "Rendered by QuickLaTeX.com") ,
,  can be rewritten as:
can be rewritten as:
![J_\pi(\phi) = \mathbb{E}_{s_t \sim \mathcal{D}, a_t \sim \pi_\phi}[\log \pi_\phi(a_t | s_t) - Q_\theta(s_t, a_t)]](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-ef7e892a4de4497d3a6a56ae0b2ade2e_l3.png "Rendered by QuickLaTeX.com")
However, actions are sampled from the policy network’s output, which are represented as a stochastic node in the computation graph. Gradient cannot be backprogagated unless we use “reparameterization trick” to make the action node a deterministic node. In other word, actions will be outputted from a deterministic function  with a stochastic input
with a stochastic input  . This trick is also widely used in variational autoencoders, and has been discussed in [11, 13, 14, 15, 16] . Reparameterization trick can also be illustrated in the diagram below [11]:
. This trick is also widely used in variational autoencoders, and has been discussed in [11, 13, 14, 15, 16] . Reparameterization trick can also be illustrated in the diagram below [11]:
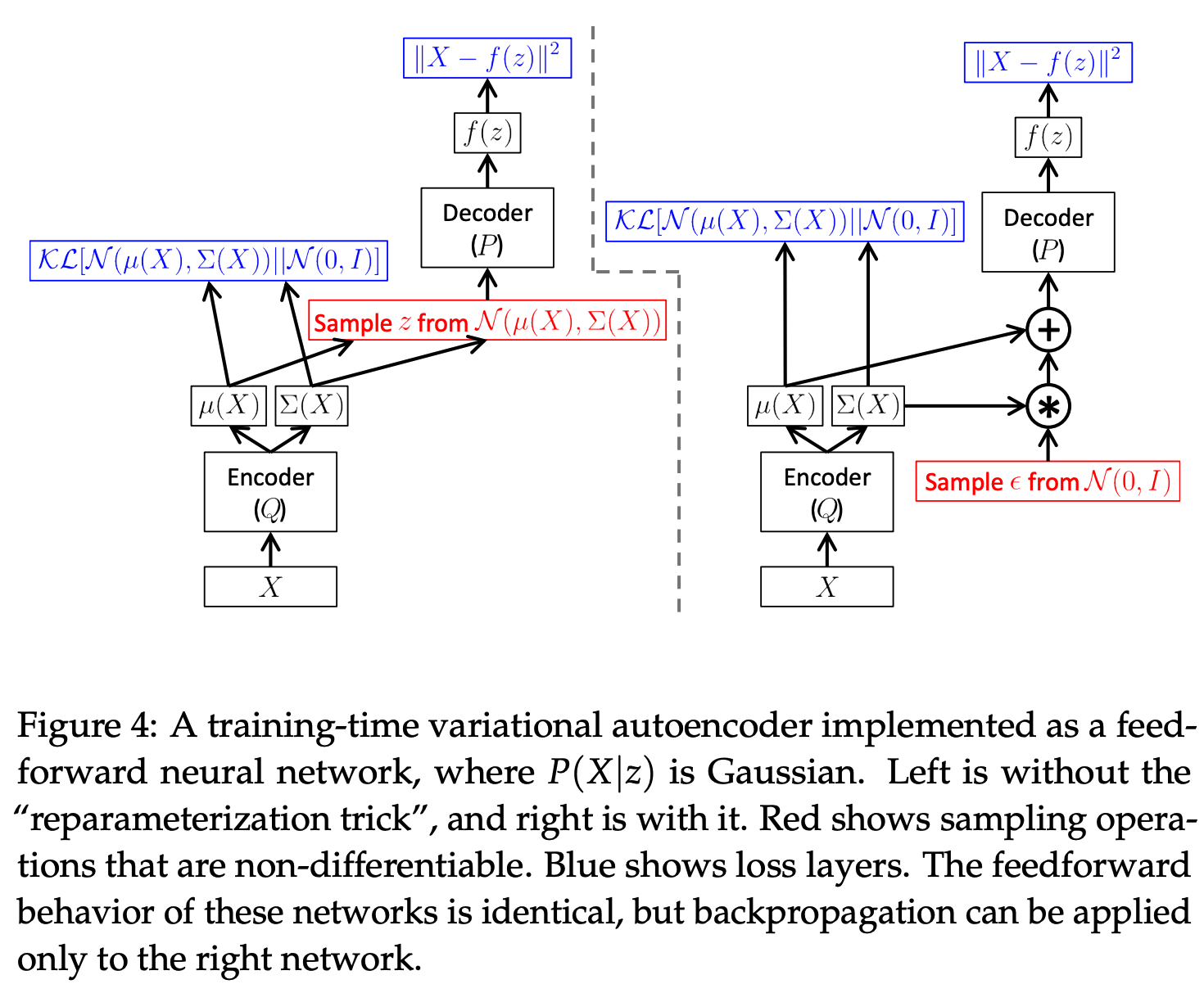
After applying reparameterization trick, we have the stochastic gradient, for a training tuple  :
:
![\hat{\nabla}_\phi J_\pi(\phi) \newline = \nabla_\phi [\log \pi_\phi(a_t | s_t) - Q_\theta(s_t, a_t)] |_{a_t = f_\phi(\epsilon_t ; s_t)} \newline = (\nabla_{a_t} \log \pi_\phi(a_t | s_t) - \nabla_{a_t} Q_\theta (s_t, a_t)) \nabla_\phi f_\phi(\epsilon_t; s_t)](https://czxttkl.com/wp-content/ql-cache/quicklatex.com-ba5b4816d2d2c65a2dab0360ec29f073_l3.png "Rendered by QuickLaTeX.com")
I think what I derived above is a little different than Eqn.(13) in the paper, which has an extra  . Right now I am not sure why but I will keep figuring it out.
. Right now I am not sure why but I will keep figuring it out.
In applications where output actions need to be squashed to fit into some ranges,  also needs to account that. Basically, if squashed action = squash function(raw_action), then the probability density of squashed actions will be different than the probability density for raw actions [17]. The original code reflects this in https://github.com/haarnoja/sac/blob/fba571f81f961028f598b0385d80cb286d918776/sac/policies/gaussian_policy.py#L70-L75.
also needs to account that. Basically, if squashed action = squash function(raw_action), then the probability density of squashed actions will be different than the probability density for raw actions [17]. The original code reflects this in https://github.com/haarnoja/sac/blob/fba571f81f961028f598b0385d80cb286d918776/sac/policies/gaussian_policy.py#L70-L75.
SAC’s learning pattern is summarized as follows:
- It evaluates the soft Q-value function and the soft value function. Both functions are associated with the train policy but can still be learned through the data collected by the behavior policy.
To estimate the soft value function, we can draw states from experience replay generated by the behavior policy, and use the action generated by the train policy.

To estimate the Q-value function, we can just use states and actions both drawn from the experience replay:

2. It updates the policy parameters, with the goal to minimize the expected KL-divergence between the current policy outputs and the exponential of the soft Q-value function.
3. Loop back to step 1
Thee pseudocode is as follows:

Lastly, I am using the slides for soft actor-critic paper to end this post [12].
References
[1] Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., … & Kavukcuoglu, K. (2016, June). Asynchronous methods for deep reinforcement learning. In International conference on machine learning (pp. 1928-1937). https://arxiv.org/pdf/1602.01783.pdf
[2] Policy gradient: https://czxttkl.com/?p=2812
[3] Differences between on-policy and off-policy: https://czxttkl.com/?p=1850
[4] https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html#soft-actor-critic
[5] Off-Policy Actor-Critic: https://arxiv.org/abs/1205.4839
[6] http://mlg.eng.cam.ac.uk/teaching/mlsalt7/1516/lect0304.pdf
[7] https://czxttkl.com/?p=2616
[8] http://users.isr.ist.utl.pt/~mtjspaan/readingGroup/ProofQlearning.pdf
[9] https://www.cs.cmu.edu/~katef/DeepRLControlCourse/lectures/lecture3_mdp_planning.pdf
[10] Kreyszig, E. (1978). Introductory functional analysis with applications (Vol. 1). New York: wiley.
[11] Tutorial on Variational Autoencoders
[12] slides for soft actor-critic
[14] Reparameterization Trick Notebook
[15] The Reparameterization “Trick” As Simple as Possible in TensorFlow
[16] arxiv insight: variational autoencoders
[17] Change of variable in probability density
[18] https://czxttkl.com/2020/02/18/practical-considerations-of-off-policy-policy-gradient/
“I think what I derived above is a little different than Eqn.(13) in the paper, which has an extra \nabla_\phi \log \pi_\phi(a_t|s_t). Right now I am not sure why but I will keep figuring it out.”
The missing item is due to the following reason:
The gradient operator should be moved inside the expectation (not directly interchange) before the sampling.
Please refer to https://medium.com/@amiryazdanbakhsh/gradients-of-the-policy-loss-in-soft-actor-critic-sac-452030f7577d