Let’s say we have predictor variables (features) denoted as $latex X \in \mathbb{R}^n$ and response variable (label) $latex y$ whose underlying random variable is $latex Y$. If we want to fit an Ordinary Least Square (OLS) regression such that $latex y=WX+\epsilon$ where $latex \epsilon$ is an error term, then we have the following assumptions:
- strict exogenous: $latex E(\epsilon|X)=0$ (error is not correlated with data itself, i.e., error comes from outside system)
- spherical error: $latex Var(\epsilon|X)=\sigma^2 I_n$ (variance on each dimension should be the same.)
- … More on wikipedia
If we think $latex Y$, rather than growing linearly as X does, actually grows exponentially, then we have $latex E[log (Y)|X] = WX$. We can treat $latex y’ = log(y)$ and fit a new OLS regression. However, the problem is that when $latex WX$ is smaller than 0, it causes predicted $latex \hat{y}’$ smaller than 0, which makes no sense given it is the result of log.
Although we can ignore this in practice if fit is already good, the alternative is to fit a Poisson regression. $latex Y \sim \text{Poisson Distribution}(WX)$, i.e.,
$latex \lambda := E(Y|X;W)=e^{WX} \\ p(y|X;W)=\frac{\lambda^y}{y!}e^{-\lambda}= \frac{e^{yWX} \cdot e^{-e^{WX}}}{y!} &s=2$
We can learn $latex W$ by doing optimization to maximize the overall likelihood.
The advantage of using Poisson distribution/regression is that it automatically deals with non-negative properties. No matter how small $latex Wx$ is, $latex y$ will always be positive. This can be illustrated through the following plot from wikipedia:
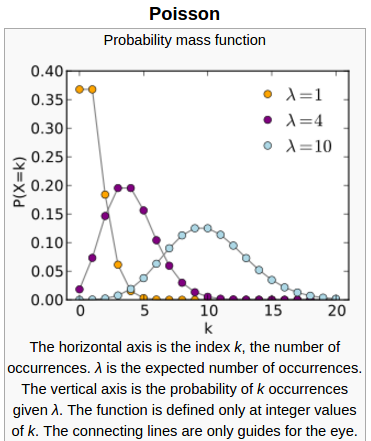
Replace y axis’ title with $latex p(y|x;W)$. We find that if $latex \lambda$ is small (e.g., close to 1), $latex p(y|x;W)$’s probability mass will be concentrated around 0 but still strictly larger than 0. When $latex \lambda$ is close to 4, $latex p(y|x;W)$’s probability mass is a skewed peak. When $latex \lambda$ is becoming larger, then the shape of $latex p(y|x;W)$’s distribution is similar to a normal distribution.
The strong assumption brought by Poisson regression is that $latex E(Y|X;W)=Var(Y|X;W)$. If this assumption does not hold, you may have a poor fit. For example, there is a phenomenon called overdispersion: When $latex WX$ is large, $latex Var(Y|X;W)>E(Y|X;W)$ due to the inability of the model to account for the complication when data values are extreme. People have applied various models, such as negative binomial model or zero-inflated model, to fit the data if Poisson regression dose not suit. See: http://www.ats.ucla.edu/stat/stata/seminars/count_presentation/count.htm
Now, let’s look at one of the models, negative binomial model. In this model, the mean of $latex log(Y)$ is accounted by both $latex WX$ and an unobserved error term $latex \epsilon$:
$latex E[Y|X, \epsilon;W] = e^{WX+\epsilon}= e^{WX} \cdot e^{\epsilon} = \mu \cdot \tau \\ p(y|X,\tau;W)= \frac{e^{-\mu\tau} \cdot (\mu\tau)^y}{y!}&s=2$
If we assume $latex \tau$ follows a gamma distribution, i.e. $latex p(\tau;\theta) \sim gamma(\theta, \theta)$, then:
$latex p(y|X;W) = \int_{0}^{\infty} p(y|X, \tau;W) p(\tau;\theta) d\tau \\= \frac{\Gamma(y+\theta)}{y!\Gamma(\theta)}(\frac{\theta}{\theta+\mu})^\theta (\frac{\mu}{\theta+\mu})^y &s=2$
We integrate out $latex \tau$ resulting to a negative binomial distribution, with:
$latex E[Y|X] = \mu \\ Var[Y|X] = \mu + \frac{\mu^2}{\theta} &s=2$
Therefore, the negative binomial model bypasses the restriction that $latex E[Y|X] = Var[Y|X]$ by introducing a new parameter $latex \theta$ to make the model more flexible when fitting to data.
Although Poisson regression originally assumes y should be positive integers (that’s why we often hear that Poisson regression is for count data), there are techniques to allow y to be positive real values. See http://stats.stackexchange.com/questions/70054/how-is-it-possible-that-poisson-glm-accepts-non-integer-numbers
Reference:
http://stats.stackexchange.com/questions/3024/why-is-poisson-regression-used-for-count-data